前言
Flux.1-dev 是目前开源界最强的文生图模型,但其高达 24GB+ 的参数量让 24G 显存(如 3090/4090)环境极易崩溃。本教程整理自真实踩坑记录,教你如何利用 ModelScope 极速下载、身份自动鉴权和显存顺序卸载技术,在单卡环境下完美复现。
1. 核心依赖搭建
为了规避后续出现的 sentencepiece 缺失、PEFT 后端未找到等报错,请务必先一次性执行以下安装:- # 1. 升级核心库
- pip install --upgrade diffusers transformers accelerate
- # 2. 安装分词与 LoRA 后端(必须安装,否则模型加载会报错)
- pip install sentencepiece protobuf peft
- # 3. 安装下载加速工具
- pip install modelscope huggingface_hub
Flux.1-dev 是受限模型,必须完成身份验证才能下载。
2.1 官网授权
- 登录 Hugging Face。
- 访问 FLUX.1-dev 页面,点击 "Agree and access repository"。(由于我已经点击过了,所以这边用FLUX.2的界面做个示范)
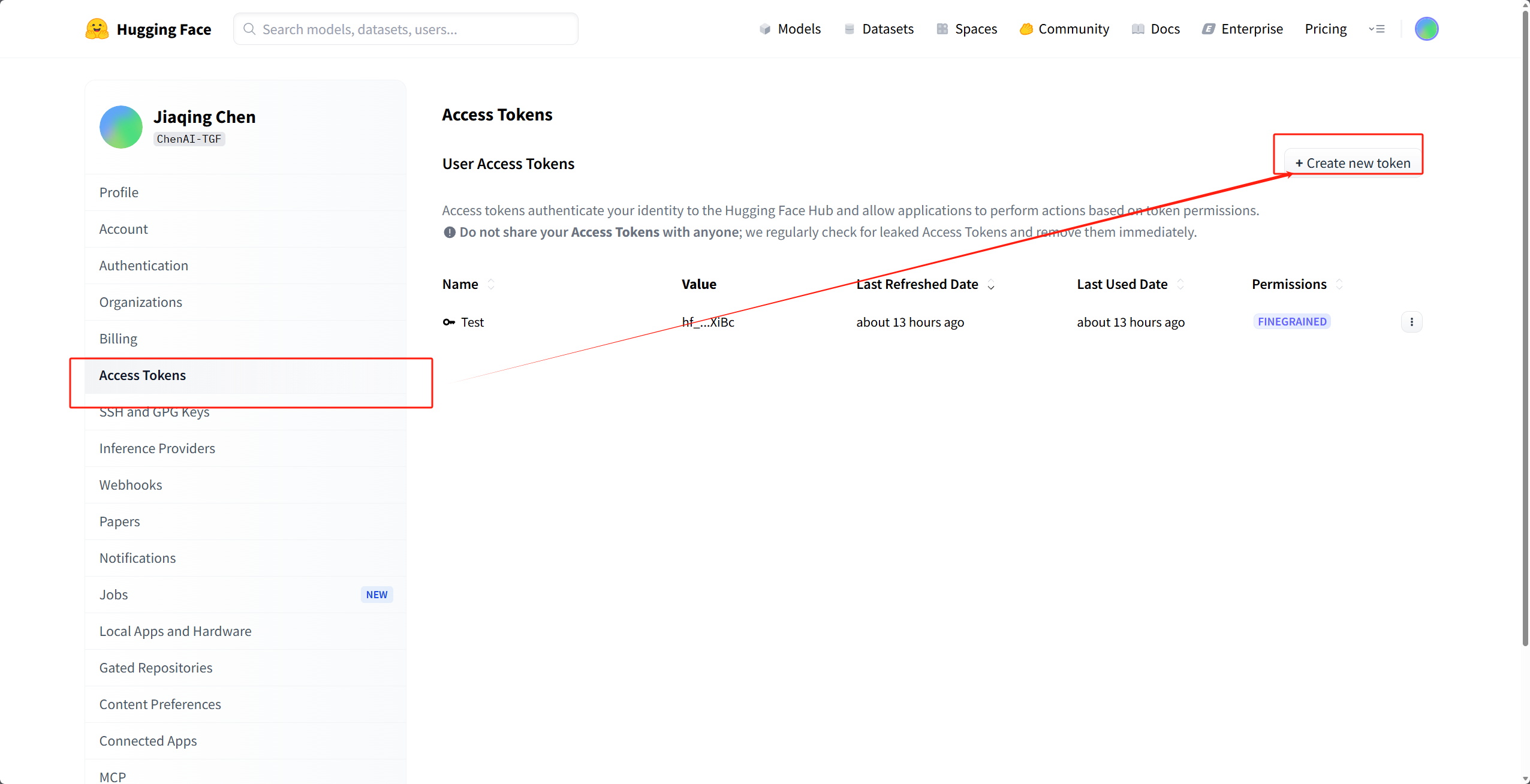
- 在 Settings -> Tokens 创建一个名为 flux 的 Read Token,并复制。
这边根据需求选就可以了,如果不理解功能的话都选也可以
2.2 终端登录鉴权
在下载模型前,必须让你的服务器“记住”你的身份:
- 提示 "Enter your token" 时:粘贴你刚才生成的 Token。注意:粘贴时屏幕不会显示任何字符,直接按回车即可。
- 提示 "Add token as git credential?" 时:输入 n。
3. 极速下载方案 (国内 CDN 提速)
利用 ModelScope 镜像站,避开 Hugging Face 官方链接每秒几百 KB 的慢速坑。
3.1 下载底模全套文件 (约 35GB)
- mkdir -p ~/workspace/FLUX.1-dev
- cd ~/workspace/FLUX.1-dev
- # 使用 ModelScope 顺序补全所有配置文件和权重
- modelscope download --model AI-ModelScope/FLUX.1-dev --local_dir .
- mkdir -p ~/workspace/lora-cockpit
- cd ~/workspace/lora-cockpit
- modelscope download --model AI-ModelScope/cockpit-360-lora-flux-dev --local_dir .
对于 24G 显存,普通加载必崩。我们必须使用 enable_sequential_cpu_offload() 这种“空间换时间”的策略。
创建 generate_360.py:- import torch
- from diffusers import FluxPipeline
- import datetime
- import os
- # 1. 显存优化:启用扩展段模式,减少碎片化
- os.environ["PYTORCH_CUDA_ALLOC_CONF"] = "expandable_segments:True"
- # 2. 本地绝对路径
- base_model_path = "/root/workspace/FLUX.1-dev"
- lora_path = "/root/workspace/lora-cockpit"
- print(f"[{datetime.datetime.now()}] 正在从磁盘加载 Flux 模型组件...")
- # 3. 初始化加载 (local_files_only 确保不联网检测)
- pipe = FluxPipeline.from_pretrained(
- base_model_path,
- torch_dtype=torch.bfloat16,
- local_files_only=True
- )
- # 4. 【核心优化】开启顺序 CPU 卸载模式
- # 它会将模型按层加载到 GPU,处理完立即卸载,是 24G 显存跑通 Flux 的唯一选择
- pipe.enable_sequential_cpu_offload()
- print(f"[{datetime.datetime.now()}] 正在注入 360° LoRA...")
- pipe.load_lora_weights(lora_path)
- # 5. 设置全景提示词与参数
- prompt = "A 360 degree equirectangular panorama of a high-tech spaceship cockpit, glowing blue console, detailed controls, stars outside, 8k"
- width = 2048
- height = 1024
- print(f"[{datetime.datetime.now()}] 推理中... (该模式下速度稍慢,请耐心等待)")
- with torch.inference_mode():
- torch.cuda.empty_cache() # 强制清理缓存
- image = pipe(
- prompt,
- width=width,
- height=height,
- num_inference_steps=28,
- guidance_scale=3.5
- ).images[0]
- # 6. 结果保存
- image.save("cockpit_360_final.png")
- print(f"[{datetime.datetime.now()}] 完成!图片已保存。")
6. 常见问题总结
- 报错 OSError: model_index.json not found:说明 ModelScope 没下全,请重新运行下载命令补全小文件。
- 报错 sentencepiece:环境里没装这个库,必须 pip install sentencepiece。
- 报错 CUDA out of memory:
- 检查分辨率是否设得太高(建议从 1024x512 开始测试)。
- 确保使用的是 enable_sequential_cpu_offload() 而不是 enable_model_cpu_offload()。
- 授权 403 错误:确保你已经在浏览器端点击过“同意协议”,且 huggingface-cli login 成功。
来源:程序园用户自行投稿发布,如果侵权,请联系站长删除
免责声明:如果侵犯了您的权益,请联系站长,我们会及时删除侵权内容,谢谢合作! |






 提升卡
提升卡 置顶卡
置顶卡 沉默卡
沉默卡 喧嚣卡
喧嚣卡 变色卡
变色卡 千斤顶
千斤顶 照妖镜
照妖镜



