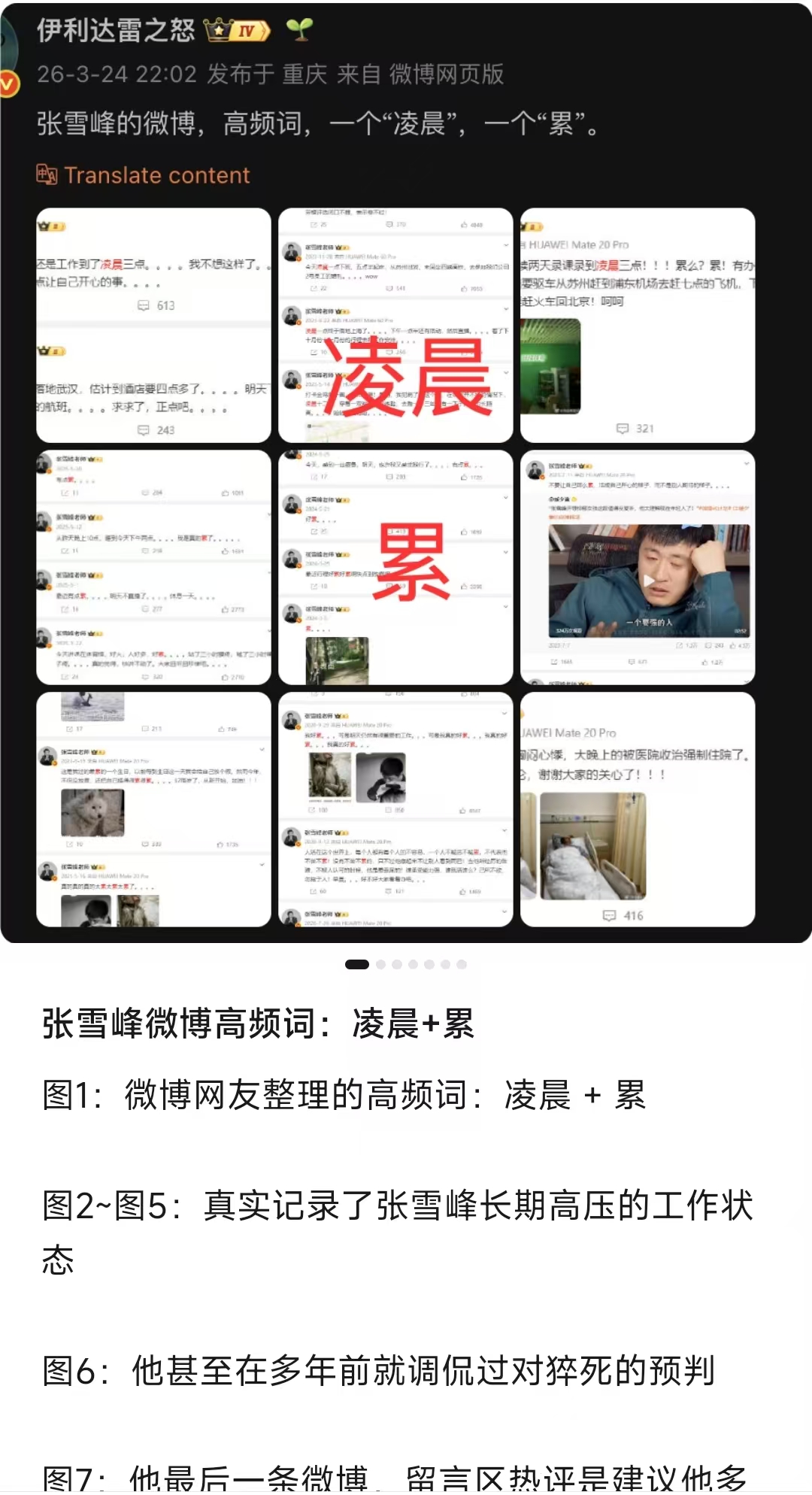
张雪峰老师的突然逝世,全网都感到无比的悲痛,他说:钱财早已不重要,能实实在在帮到普通人,才是活着的意义。为此他长期的身心透支,默默地付出着自己。
看到不少博主推送的消息,都说:张雪峰老师很累,长期拼搏到凌晨,为了验证一下这个结果,我以微博里张雪峰老师发送的微博内容使用AI全流程开发一个简单的爬虫,系统分析一下结果。
一、AI写爬虫代码
我这里使用的是trae这个开发工具,使用GPT5的模型来完成全流程开发
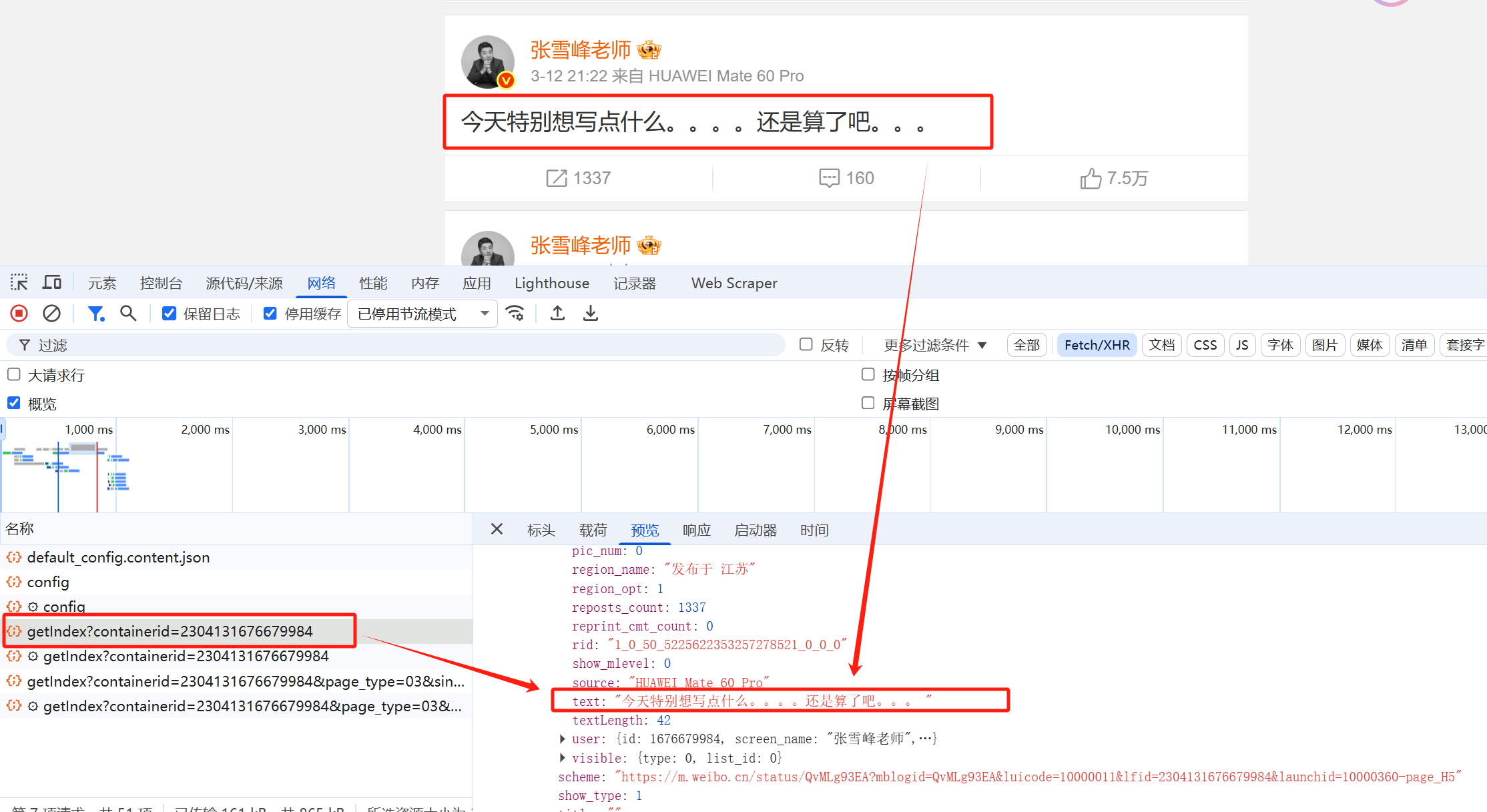
我们先来到微博的移动端,打开张雪峰老师的主页:https://m.weibo.cn/p/2304131676679984
通过搜索微博内容,我们定位到了查询微博内容的API接口如下
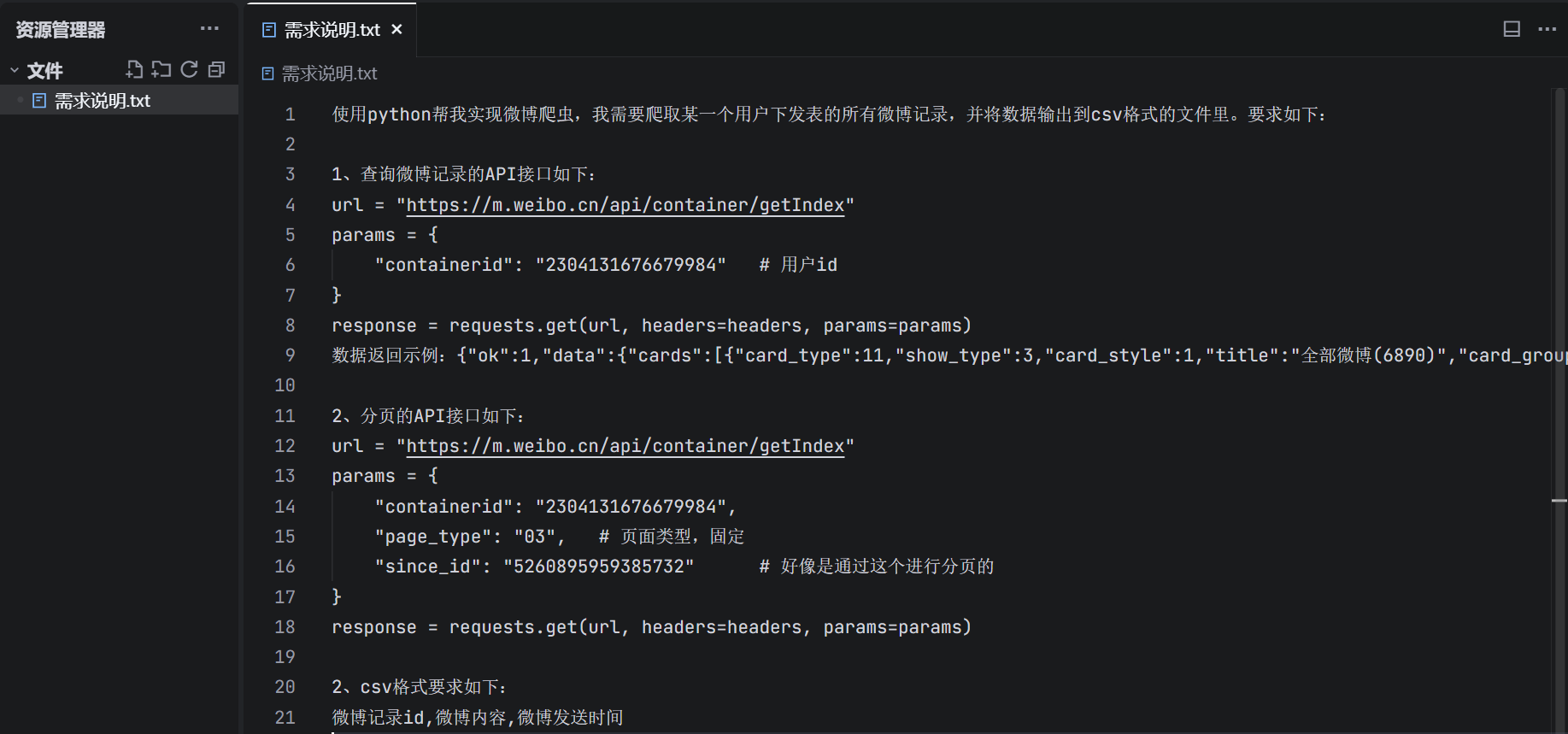
因为提示词较多,我们可以新建一个txt文档,然后编写好对应的微博爬虫需求,并提供API示例给到AI
提示词如下:- 使用python帮我实现微博爬虫,我需要爬取某一个用户下发表的所有微博记录,并将数据输出到csv格式的文件里。要求如下:
- 1、查询微博记录的API接口如下:
- url = "https://m.weibo.cn/api/container/getIndex"
- params = {
- "containerid": "2304131676679984" # 用户id
- }
- response = requests.get(url, headers=headers, params=params)
- 数据返回示例:{填写实际返回的数据}
- 2、分页的API接口如下:
- url = "https://m.weibo.cn/api/container/getIndex"
- params = {
- "containerid": "2304131676679984",
- "page_type": "03", # 页面类型,固定
- "since_id": "5260895959385732" # 好像是通过这个进行分页的
- }
- response = requests.get(url, headers=headers, params=params)
- 2、csv格式要求如下:
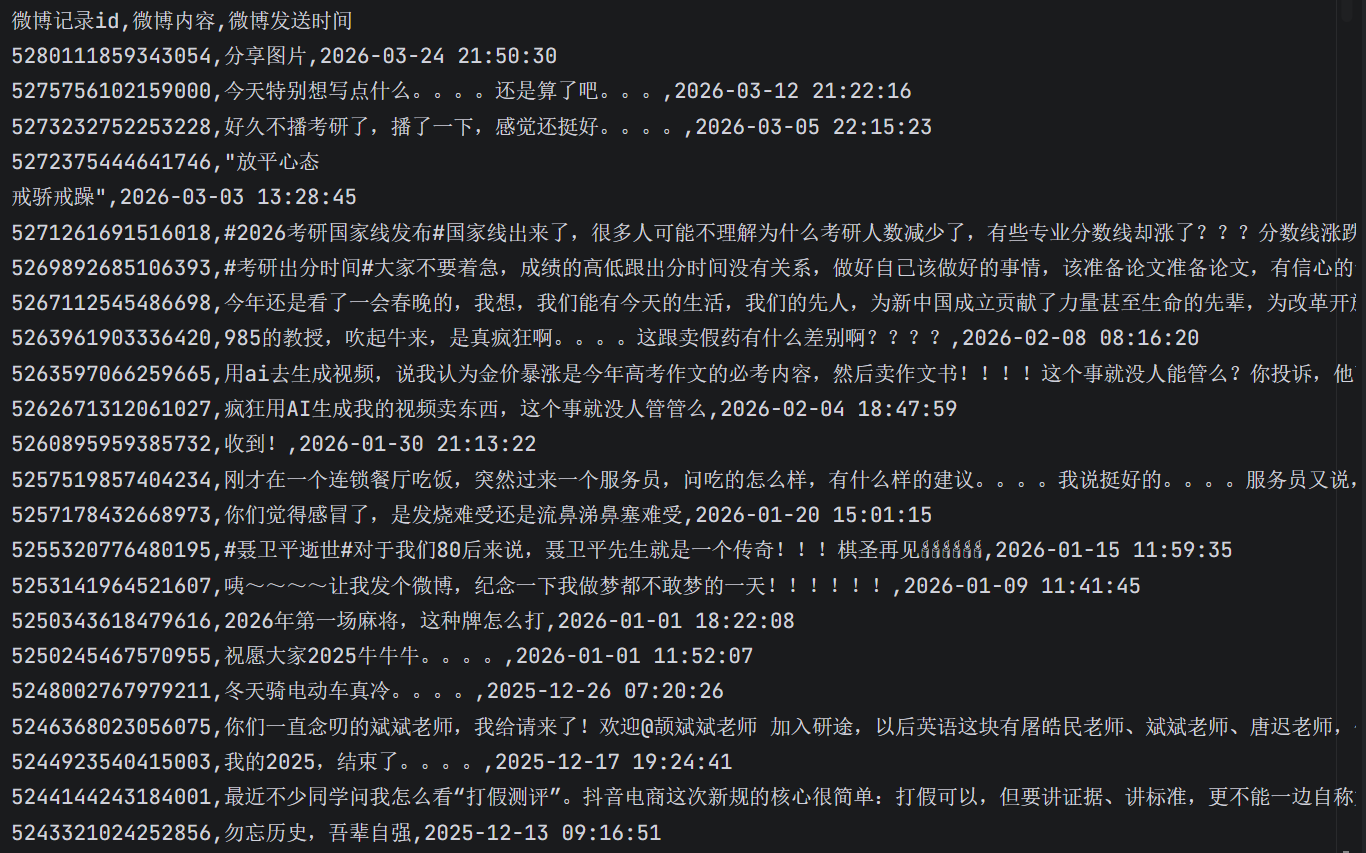
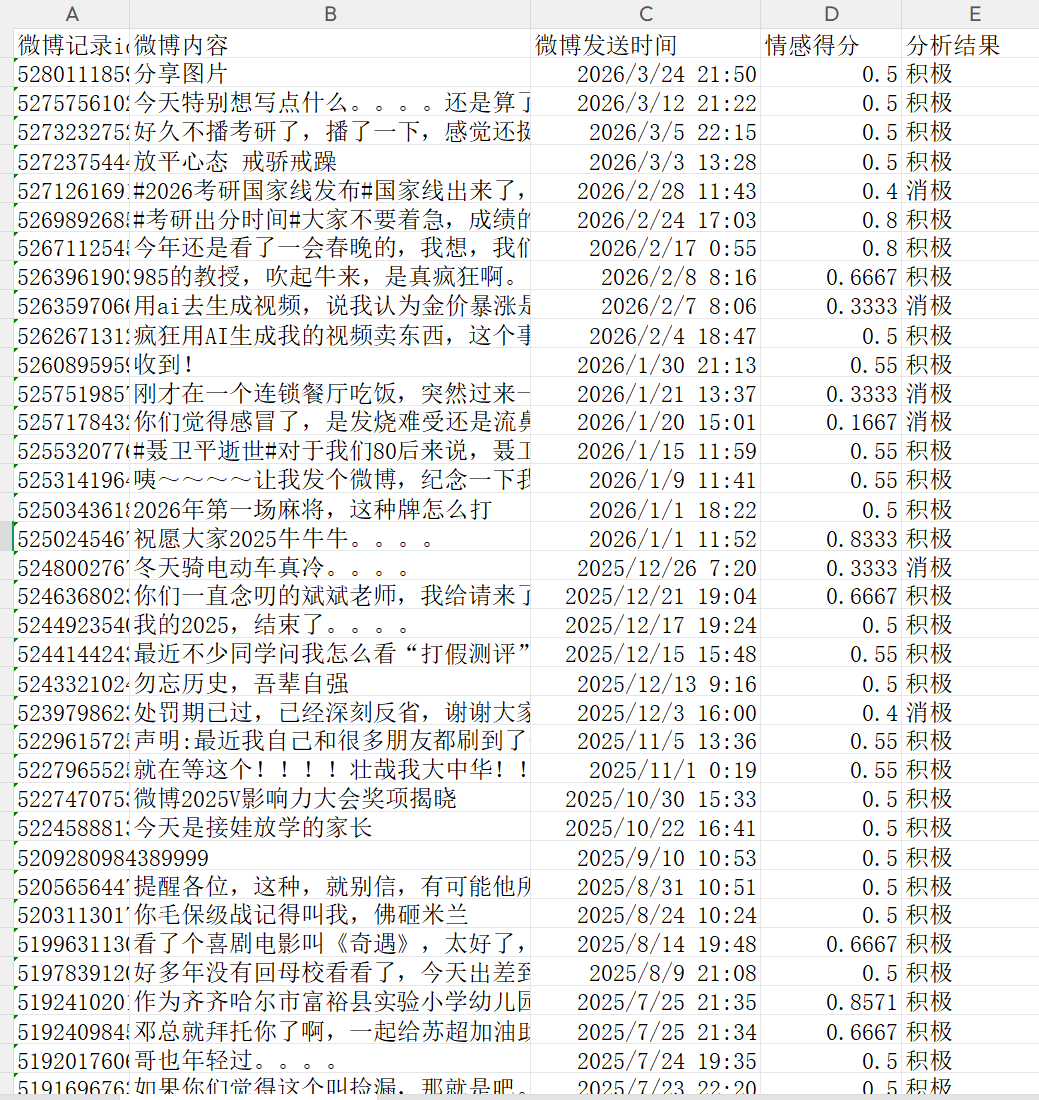
- 微博记录id,微博内容,微博发送时间
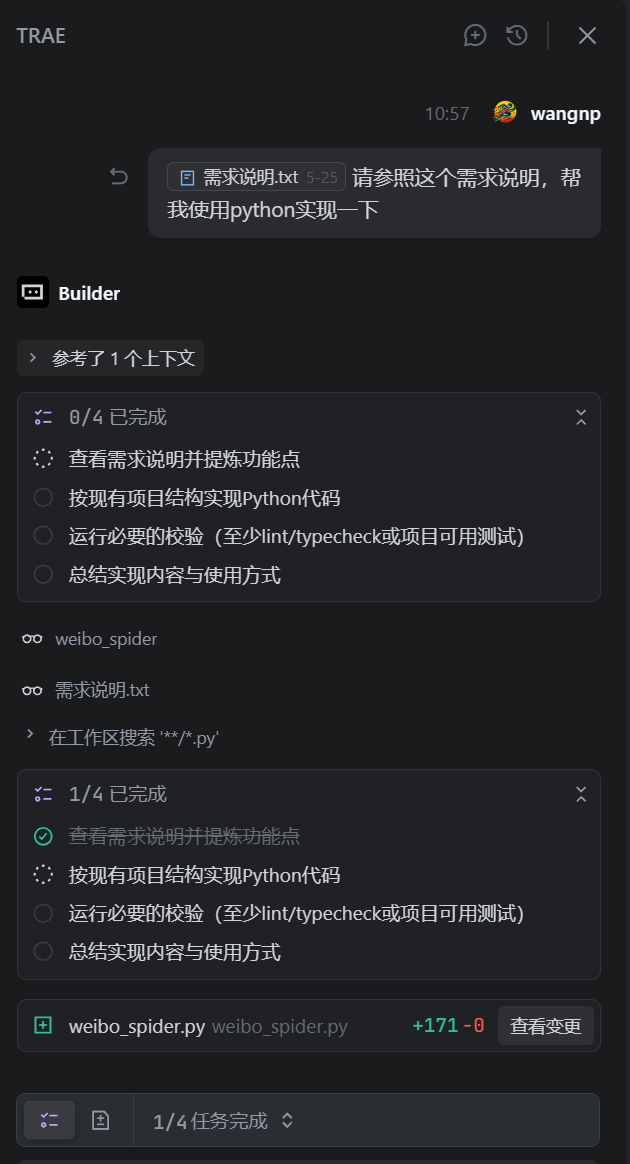
接下来,就是静静地等待了,你可以去摸摸鱼,散个步放松一下心情,
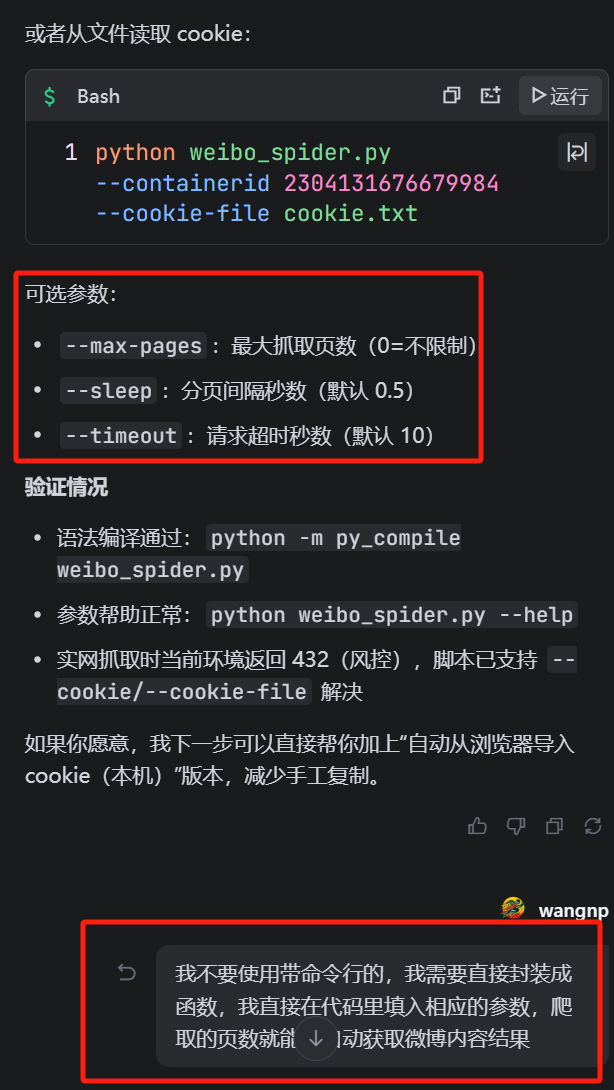
他给了我带命令行的版本,可是我本人并不喜欢命令行这种方式,我喜欢直接在代码里填入参数的方式。
于是我告诉他的提示词如下:- 我不要使用带命令行的,我需要直接封装成函数,我直接在代码里填入相应的参数,爬取的页数就能够自动获取微博内容结果
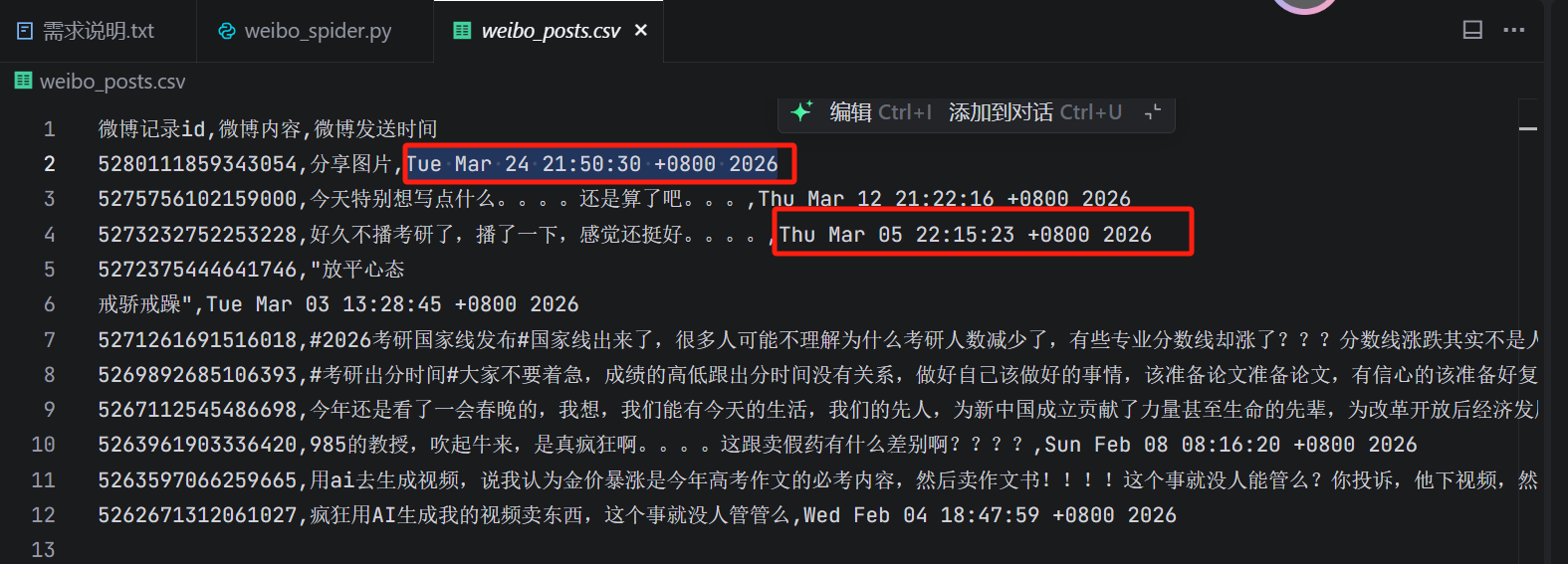
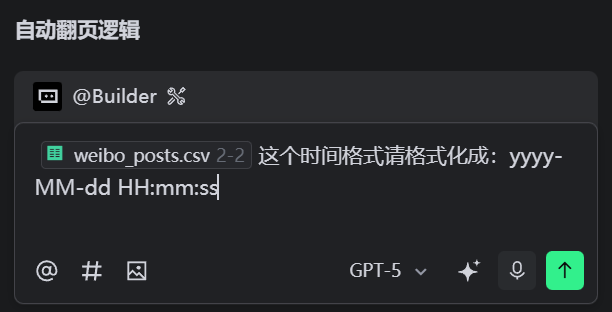
我们来运行一下代码,跑一下看看,输出了一个weibo_posts.csv的文件,我们打开看一眼,已经基本上满足了我们的要求,但是发现时间格式不正确,我希望把时间格式化成:yyyy-MM-dd HH:mm:ss这种格式的。
于是我给了他下面的提示词:- weibo_posts.csv 2-2 这个文件的时间格式请格式化成:yyyy-MM-dd HH:mm:ss
很快他就帮我改好了代码,并输出了正确的结果。这是爬取下来的部分结果:
写完爬虫这部分的代码所花费的时间不到10分钟,不得不说,AI开发效率是真的提升巨大!
二、AI生成词云图
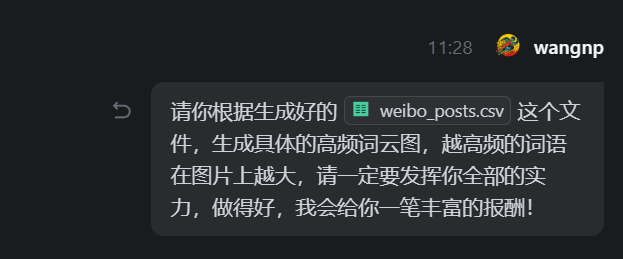
紧接着,我们生成一下词云图,AI提示词如下,在这里,我的习惯是:鼓励一下AI,并承诺做得好,给他大大的奖励!- 请你根据生成好的weibo_posts.csv这个文件,生成具体的高频词云图,越高频的词语在图片上越大。
- 请一定要发挥你全部的实力,做得好,我会给你一笔丰富的报酬!
AI又开始给我干活了,我们耐心等待几分钟。
期间可能会出现AI的想法和你的想法不一致的情况,比如:
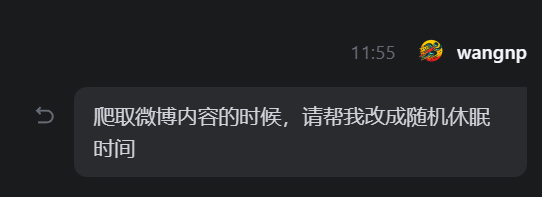
1、我希望他随机休眠时间,而不是固定1个时间
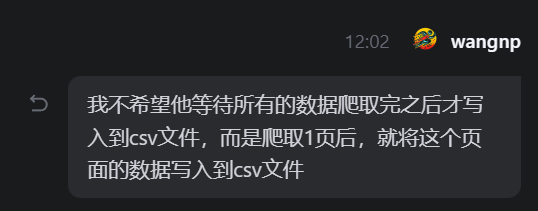
2、我希望他爬取完1页就输出到csv文件,而不是全部爬完才输出csv文件
等等.....
如果出现了,不要害怕,直接跟AI提出你的要求,让他一直改,改到你认为完美为止!
当他把代码全部改完后,我们运行一下代码:这是我用张雪峰老师2025-2026年所有的微博记录结果生成出来的词云图:
统计出来的热门高频词如下:
[('高考', 27), ('志愿', 16), ('雪峰', 16), ('考生', 12), ('知道', 12), ('夸克', 12), ('问题', 11), ('孩子', 11), ('考研', 9), ('专业', 9)]
这是2025-2026年反映情绪的形容词词频提取结果:
情感词Top10: [('疯狂', 2), ('开心', 2), ('难受', 2), ('喜欢', 2), ('着急', 1), ('欣慰', 1), ('感谢', 1), ('快乐', 1), ('满足', 1), ('紧张', 1)]
三、AI统计活跃时间段
先上提示词:- 请使用python代码,帮我统计一下:活跃时间段,是上午、下午、还是晚上更为活跃?
那我肯定是需要这个图啦,文字哪有图带来的直观效果,于是我立马让他帮我实现
实现好之后,他会告诉我如何调用,我们参照他的调用示例,运行代码即可生成活跃时间柱状图啦!
相关运行代码展示:- if __name__ == "__main__":
- # 爬取记录
- # max_page = 0
- # result = execute_spider(max_page)
- # print(f"完成: 共导出{len(result)}条记录")
- # 生成词云图
- top_words = generate_wordcloud_from_csv(csv_path='weibo_posts.csv')
- top10 = list(top_words.items())[:10]
- print("词云生成完成: weibo_wordcloud.png")
- print(f"Top10词频: {top10}")
- # 统计活跃时间段
- result = analyze_active_period_from_csv(
- csv_path=r"e:\workspace-trae\weibo_spider\weibo_posts.csv"
- )
- print("活跃时间段:", result)
- chart_result = generate_active_bar_charts_from_csv(
- csv_path=r"e:\workspace-trae\weibo_spider\weibo_posts.csv",
- period_chart_path=r"e:\workspace-trae\weibo_spider\weibo_active_period_bar.png",
- hour_chart_path=r"e:\workspace-trae\weibo_spider\weibo_active_hour_bar.png",
- )
- print("活跃时间段柱状图已输出:", chart_result)
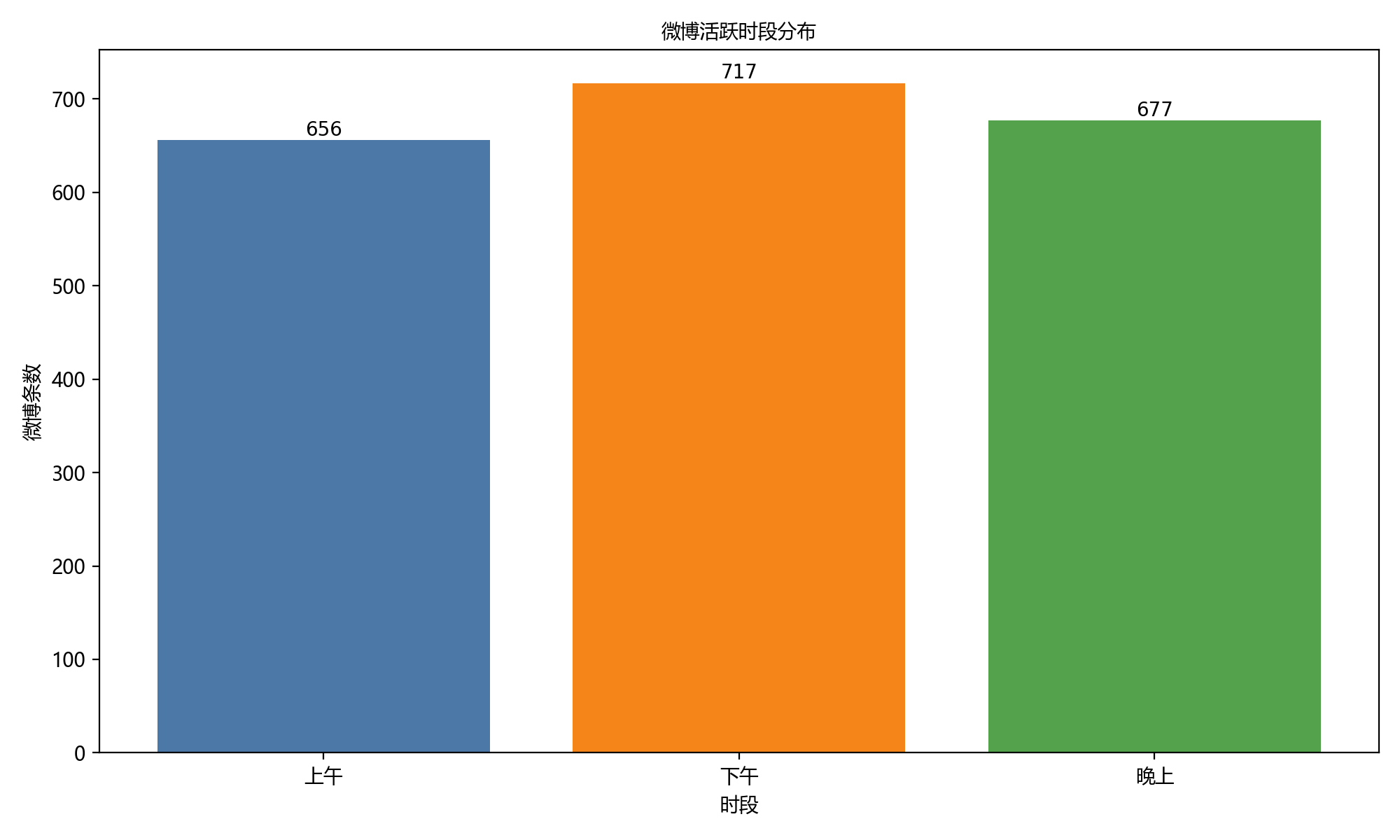
- {
- "总数": 129,
- "计数": {
- "上午": 46,
- "下午": 48,
- "晚上": 35
- },
- "占比": {
- "上午": "35.66%",
- "下午": "37.21%",
- "晚上": "27.13%"
- },
- "最活跃时段": "下午"
- }
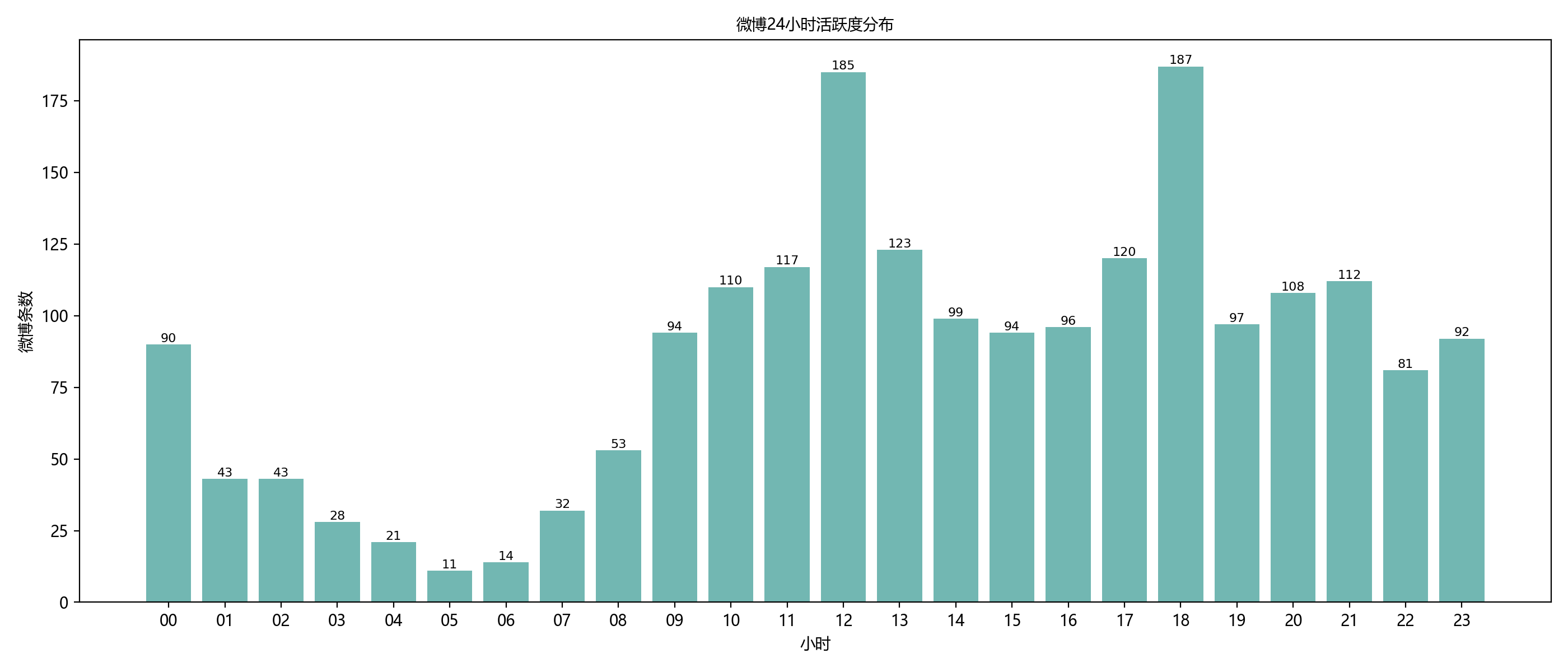
从柱状图可以看出:张雪峰老师下午开始在微博比较活跃,凌晨1-2点也还在努力拼搏中...
四、AI生成情感分析结果
先上提示词:- 请使用帮我生成情感分析结果,判断该微博内容是积极还是消极,并打分(0-1),情感分析结果输出格式:
- 微博记录id,微博内容,微博发送时间,情感得分,分析结果
2025年-2026年最终情感分析结果:- {
- "总数": 129,
- "积极": 94,
- "消极": 35,
- "积极占比": "72.87%",
- "消极占比": "27.13%",
- "输出文件": "weibo_posts_sentiment.csv",
- "模型": "规则词典"
- }
五、爬虫分析总结
2025年-2026年的微博内容分析结果,数据仅供参考:
- 情感分析打标结果:积极占比72.87%。可以看出张雪峰老师是个乐观向上的人。
- 热门高频词统计结果:"高考"、"志愿"、"考生"等是张雪峰老师非常关注的对象!"疯狂"、"开心"、"难受"、"想睡觉"等情绪词也表明雪峰老师可能存在经常熬夜的情况!
- 活跃时间段:主要分布在“下午”和“晚上”,凌晨1-2点也经常还在努力拼搏中...
他曾置身于教育资源博弈的寒冬,听过无数寒门求学者的叹息,即便身处全网质疑的暴风眼,他也未曾退缩。
他的爆火与争议,本质上是时代焦虑的缩写,是千万普通人的需求投射。
人间再无张雪峰,但他撕开现实裂缝后留下的那份真诚,以及关于“改写命运”的火种,将永远燃烧在时代深处。
致敬!张雪峰老师!
六、获取python完整源码
声明:所有爬虫代码仅用作学习用途,切勿非法使用!
我是@王哪跑,持续分享python干货,各类副业技巧及软件!
附完整版源码下载:(完整版源码下载)
来源:程序园用户自行投稿发布,如果侵权,请联系站长删除
免责声明:如果侵犯了您的权益,请联系站长,我们会及时删除侵权内容,谢谢合作! |








 提升卡
提升卡 置顶卡
置顶卡 沉默卡
沉默卡 喧嚣卡
喧嚣卡 变色卡
变色卡 千斤顶
千斤顶 照妖镜
照妖镜



