登录
/
注册
首页
论坛
其它
首页
科技
业界
安全
程序
广播
Follow
关于
导读
排行榜
资讯
发帖说明
登录
/
注册
账号
自动登录
找回密码
密码
登录
立即注册
搜索
搜索
关闭
CSDN热搜
程序园
精品问答
技术交流
资源下载
本版
帖子
用户
软件
问答
教程
代码
写记录
写博客
小组
VIP申请
VIP网盘
网盘
联系我们
发帖说明
道具
勋章
任务
淘帖
动态
分享
留言板
导读
设置
我的收藏
退出
腾讯QQ
微信登录
返回列表
首页
›
业界区
›
业界
›
Context 的本质-AI 变强背后的「信息可见性革命」 ...
Context 的本质-AI 变强背后的「信息可见性革命」
[ 复制链接 ]
呶募妙
昨天 05:30
猛犸象科技工作室:
网站开发,备案域名,渗透,服务器出租,DDOS/CC攻击,TG加粉引流
如果必须用一句话概括大模型时代最重要的工程发现,那就是:
在模型参数固定的情况下,AI 的能力上限,主要由它在推理时能够同时访问的“有效信息量”所决定。
这不是比喻。
而是一条在工程实践中反复被验证的系统规律。
理解这一点,几乎可以解释过去几年 AI 领域所有看似神奇的能力跃迁。
一、被忽略的事实
模型并不存在“思考工作区”
人们对 AI 的直觉,往往来自对人类大脑的类比。
我们很容易想象:
模型内部存在某种“工作空间”
在那里持续推理与整合信息
但真实系统结构并非如此。
实际运行方式
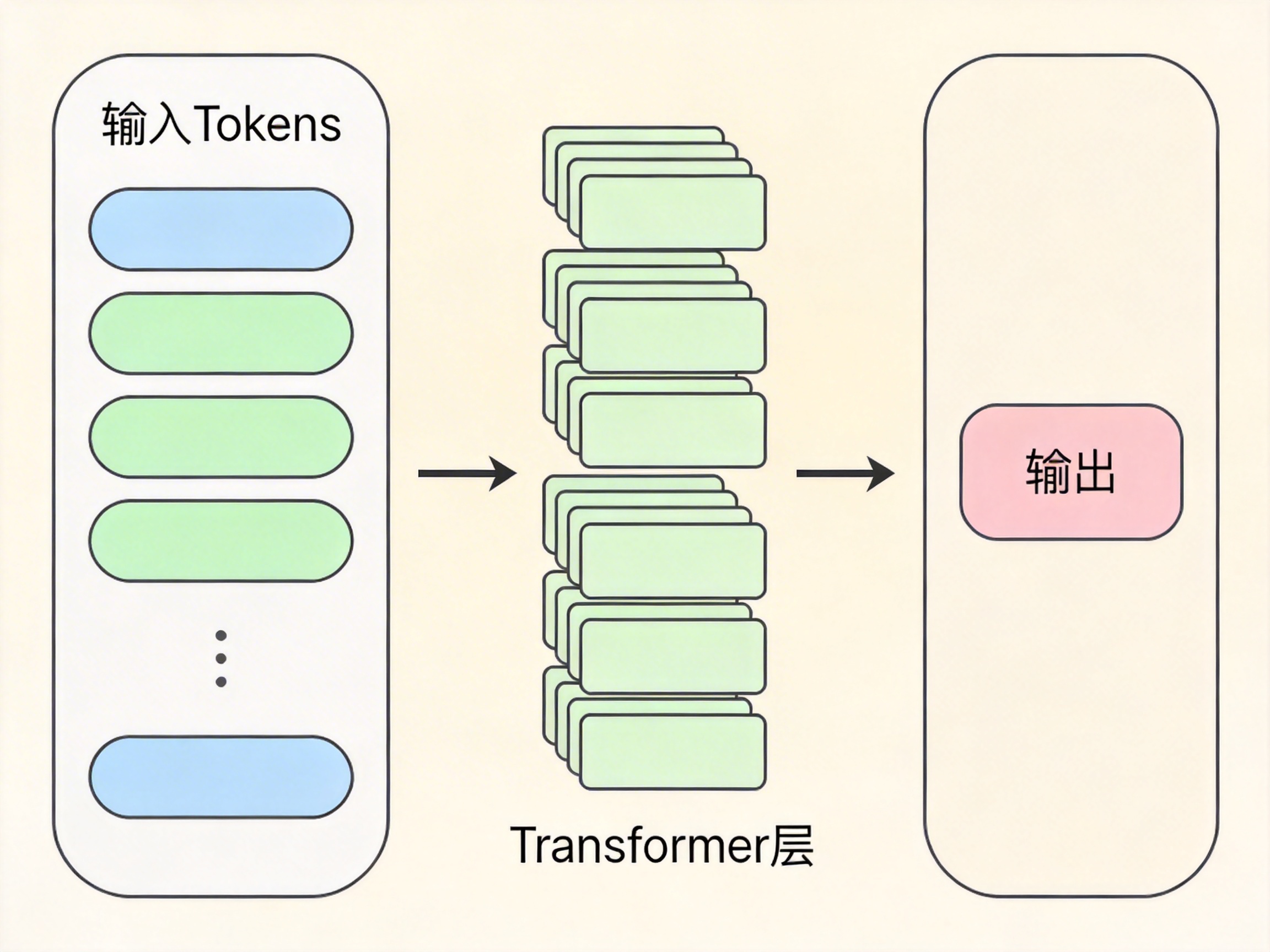
大语言模型的本质,是一次性的前馈计算:
Output = f(Input Tokens)
复制代码
在计算过程中:
Transformer 各层会形成动态的中间特征表示
这些向量承载当前上下文的信息整合结果
但它们具有两个关键特征:
✔ 只存在于当前推理过程中
✔ 不会跨上下文持续保留
核心结论
模型没有持续运作的“内部思考空间”。
每一次推理,本质上都是对当前可见信息的一次性整合计算。
二、Context 的真实定义
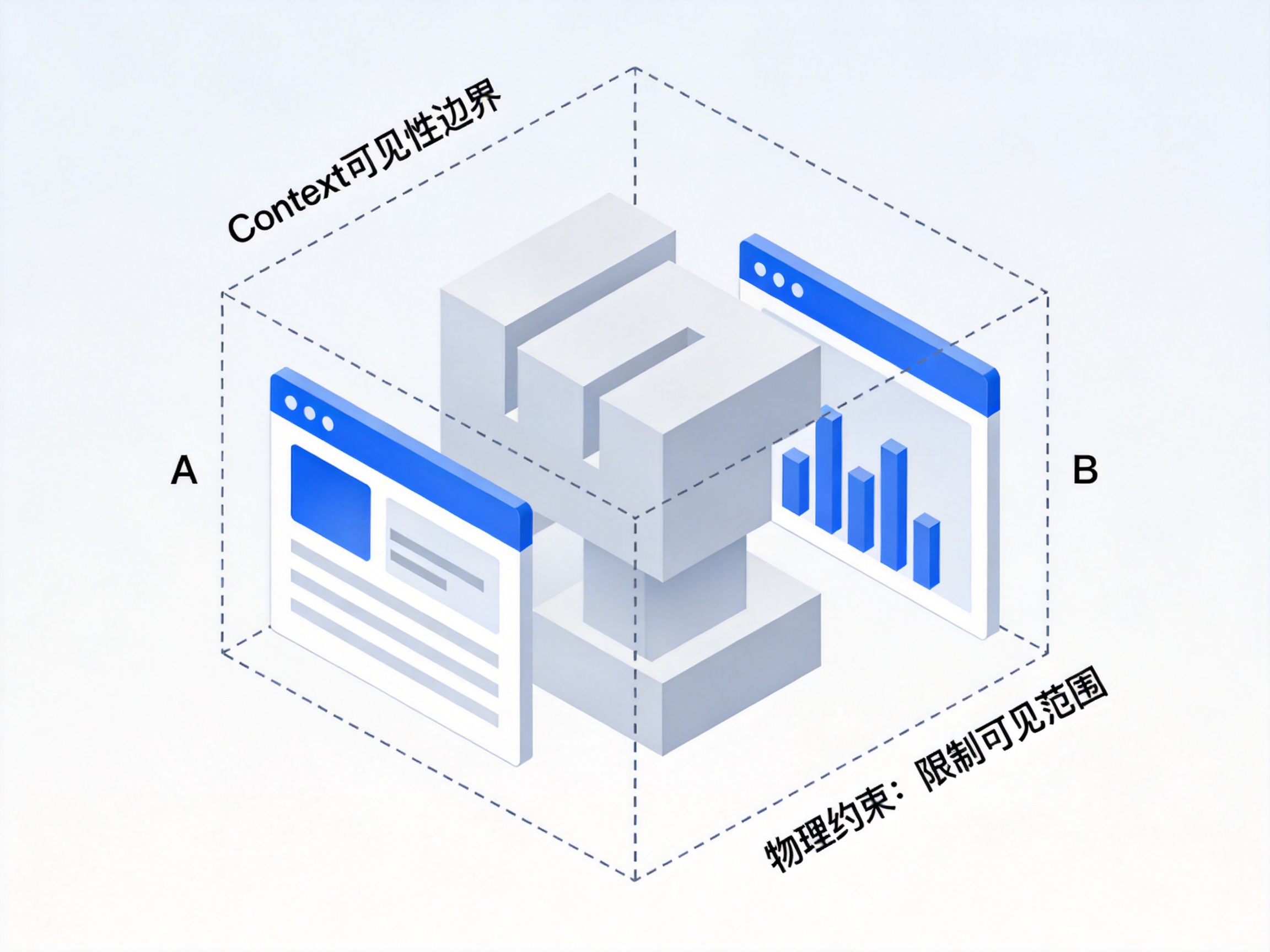
它不是记忆,而是“可见性边界”
Context 并不是存储结构。
它本质上是一种:
物理约束。
它代表的是:
模型在一次推理中可以同时访问的信息窗口。
Transformer 机制本质
在注意力机制中:
每个 token 都可以对所有可见 token 进行加权聚合。
因此:
Context 就是模型唯一的认知空间。
一个极其重要的理解
Context 并不会直接增加模型能力。
它只做一件事:
定义能力的上限边界。
模型无法理解它“看不到”的信息。
类比人类认知
心理学研究表明:
人类工作记忆容量约为
7±2 信息单元
。
对于大模型来说:
Context Window 本质上就是它的“工作记忆容量”。
三、一个关键认知转折
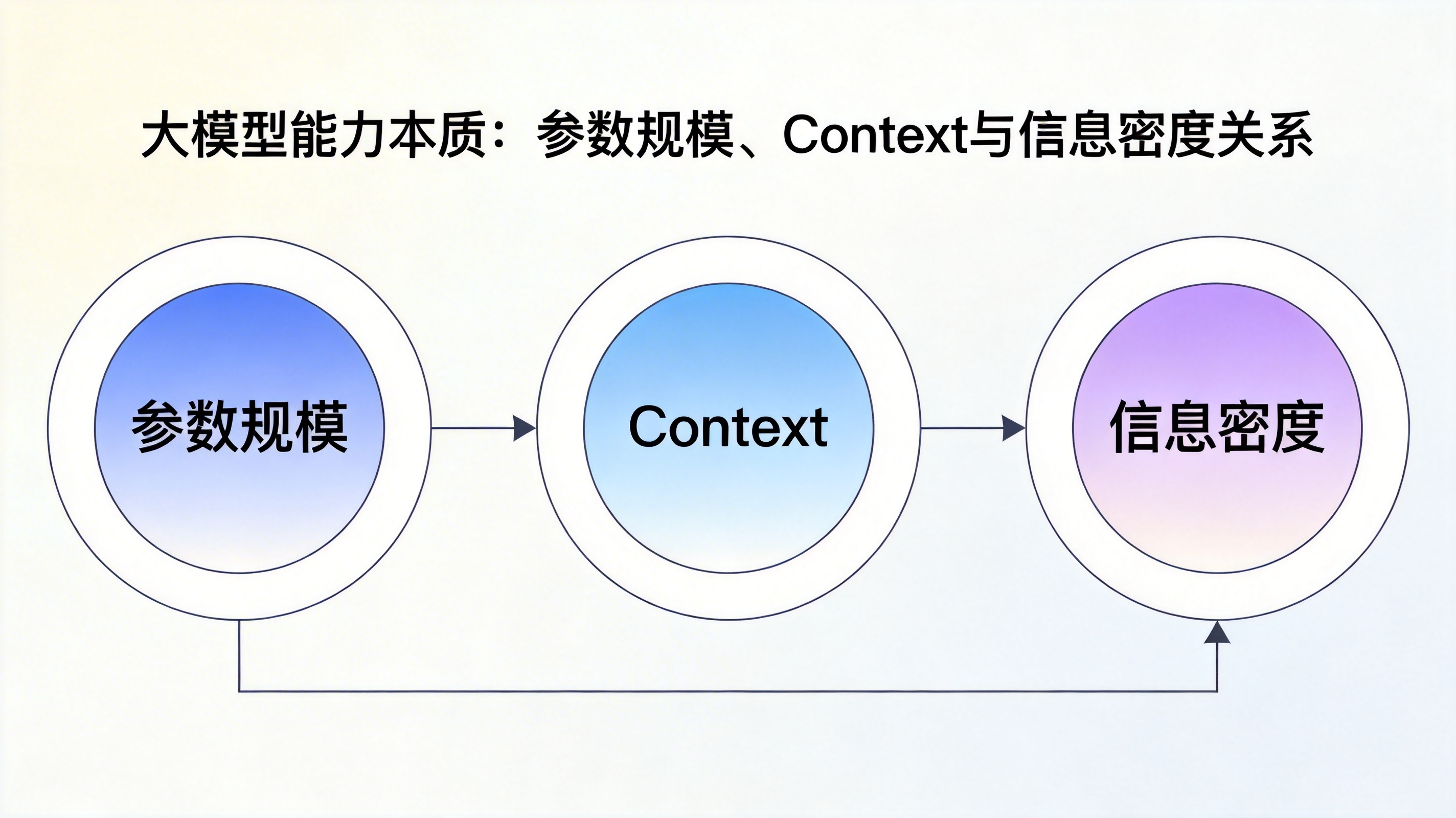
AI 能力并不只由模型规模决定
传统认知认为:
模型越大 → AI 越强
这一观点并不错误,但并不完整。
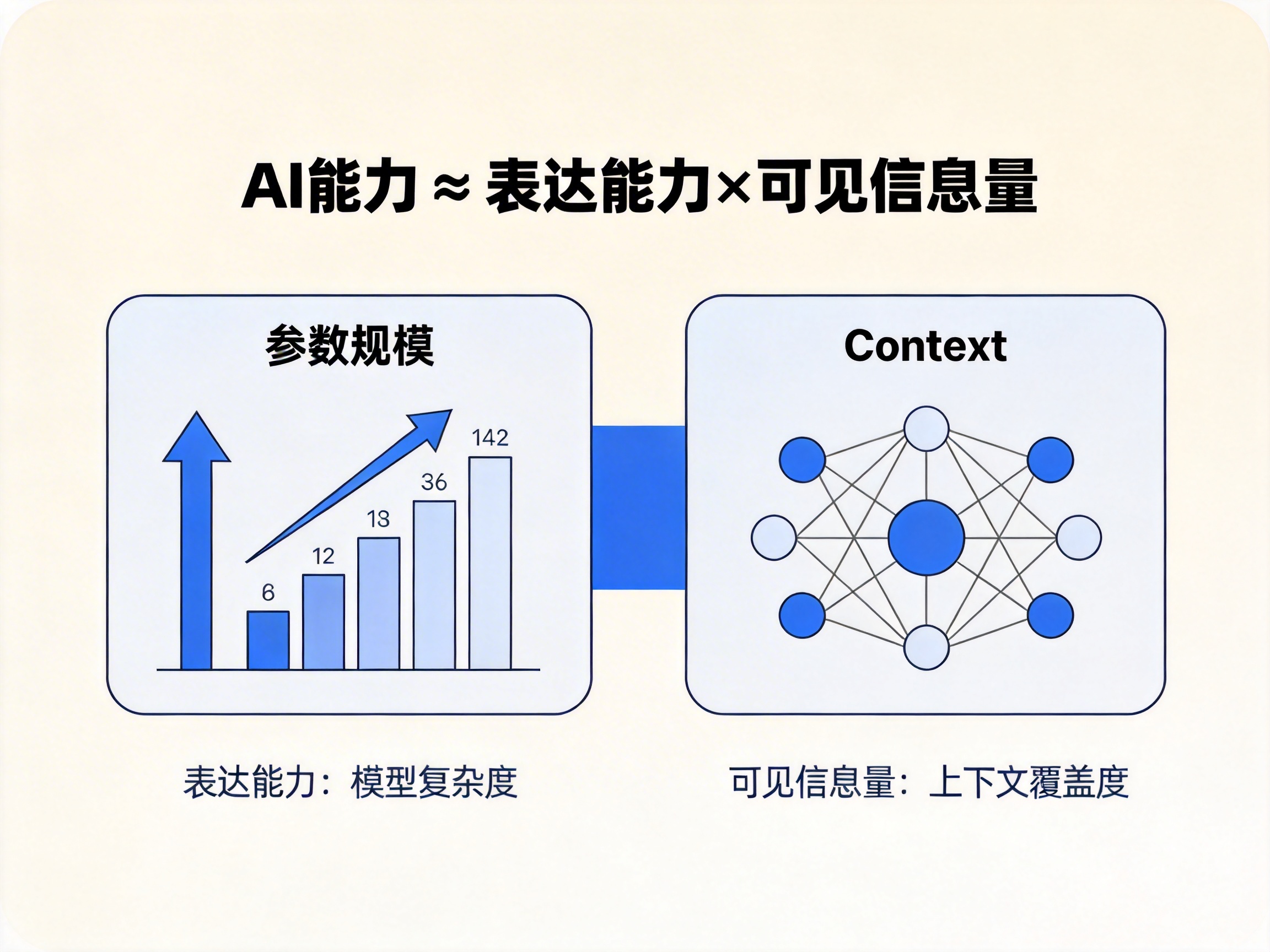
能力的真实来源 = 两个维度
参数规模 → 表达能力
决定:
能表示多复杂的模式
能学习多深层的抽象关系
Context → 认知空间
决定:
一次推理能整合多少信息
能建立多长距离的依赖关系
能力跃迁的真正条件
当表达能力足够强 + 可见信息足够多时,复杂推理能力才会真正涌现。
⭐ AI 能力本质公式
AI 能力 ≈ 表达能力 × 可见信息量
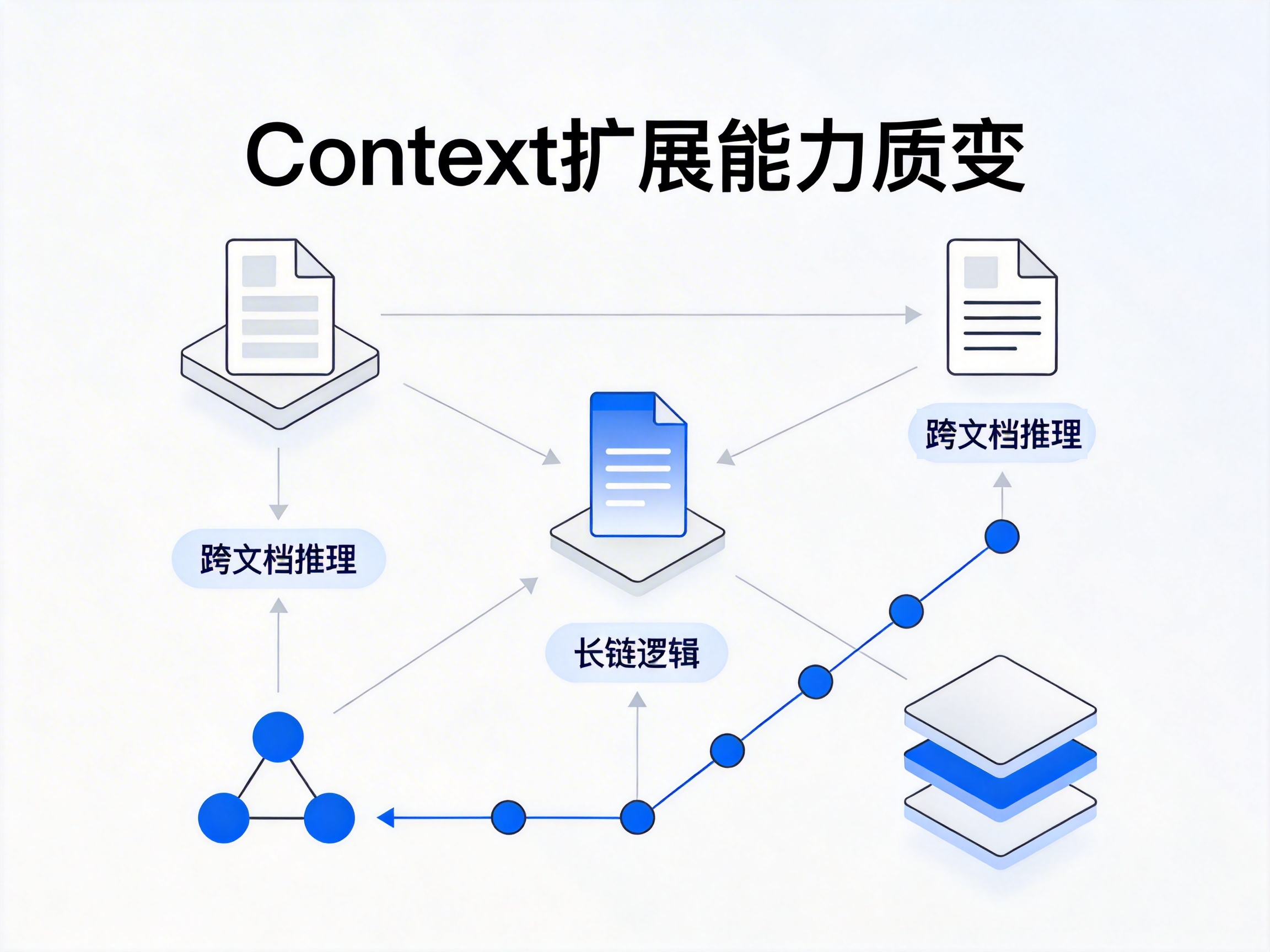
四、Context 扩展为何会引发“质变”
当 Context 从几百 token 扩展到几十万 token 时:
变化的并不是容量,而是系统性质。
模型开始表现出:
跨文档推理
长链逻辑一致性
全局结构规划
复杂任务分解
本质原因只有一个
单次推理中可利用的信息密度大幅提升。
从信息论角度:
AI 能力上限取决于可利用的信息熵,而不仅是参数规模。
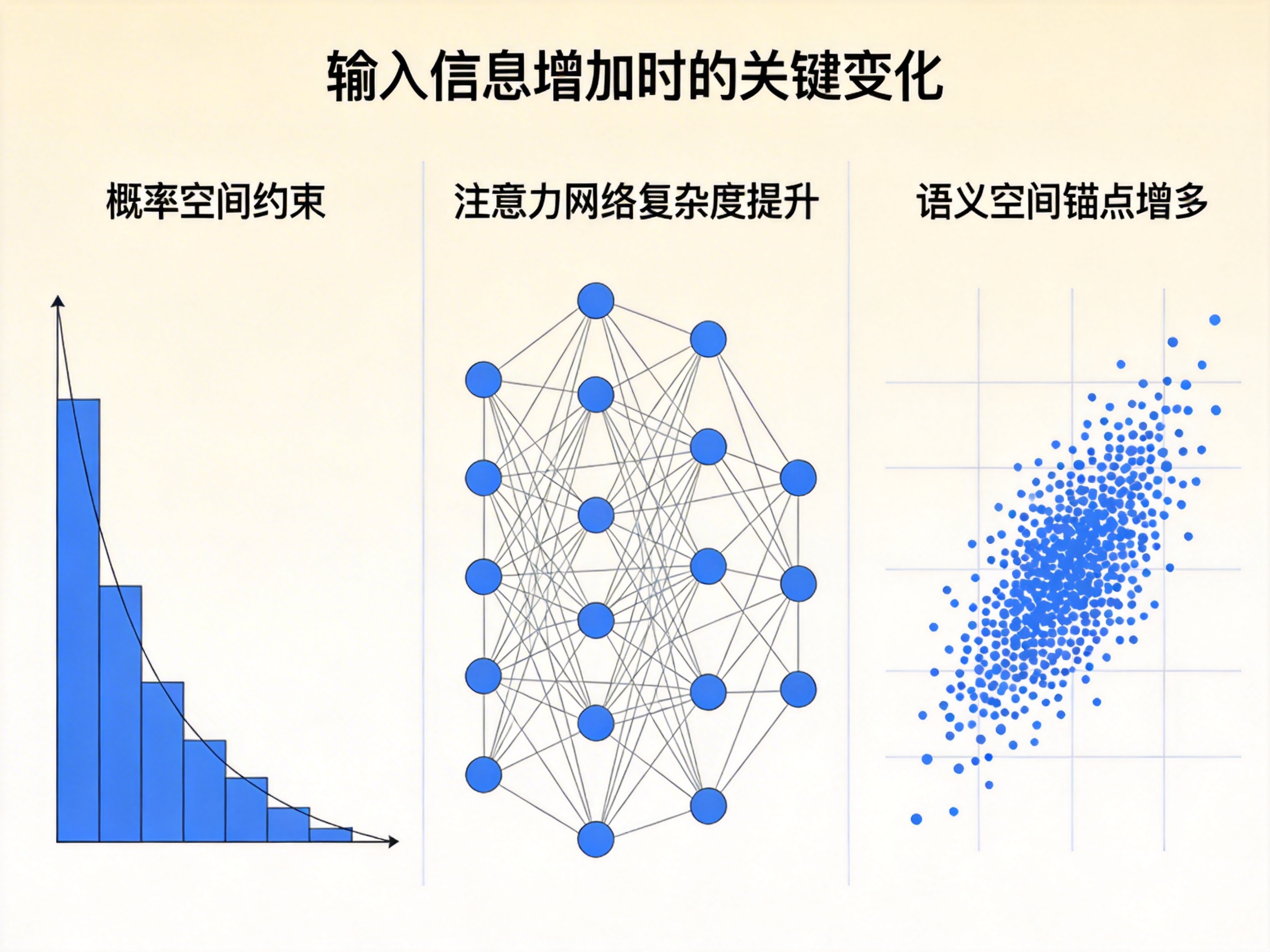
五、为什么“给更多信息”会显著提升智能?
当输入信息增加时,会发生三种关键变化。
① 概率空间被强约束
更多条件 → 概率分布收敛
结果:
不确定性降低
错误空间压缩
输出稳定性提高
② 注意力网络复杂度提升
每增加一个 token:
→ 潜在关联关系呈指数增长。
模型构建的是:
更密集的信息连接网络
这使它能:
发现远距离依赖
跨文档整合信息
执行复杂推理
③ 语义空间锚点增多
信息越丰富:
语义定位越精确
推理路径越稳定
输出一致性越高
本质上:
更多信息 = 更稳定的语义坐标系
六、Context 定律
AI 工程设计的第一原则
从工程角度看,可以得到一个极其清晰的结论:
大模型不仅是计算系统,更是信息可见性系统。
它的核心限制往往不是算力,而是:
推理时可同时访问的信息量。
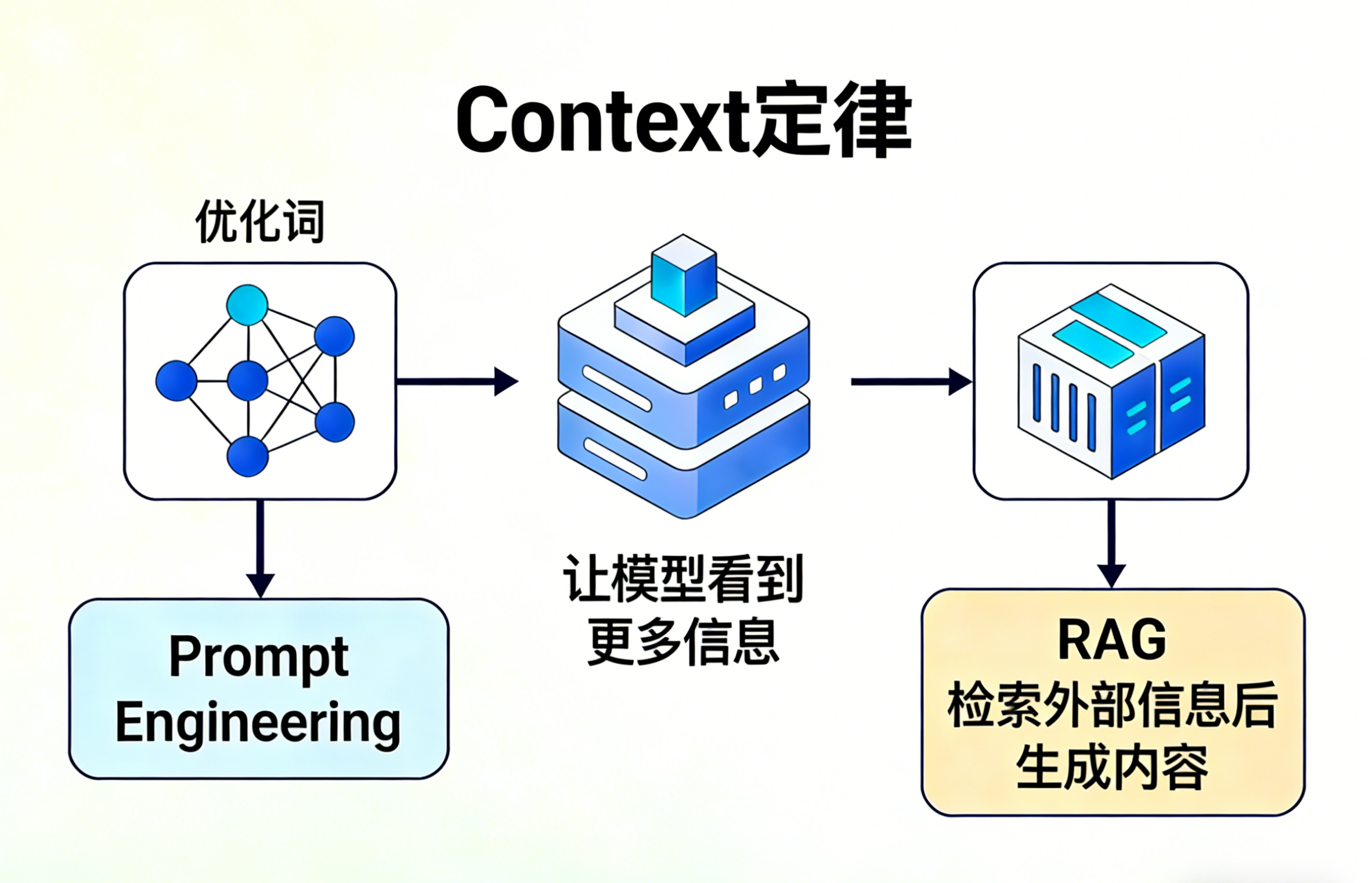
所有 AI 工程技术的共同本质
过去几年关键技术看似不同:
Prompt Engineering
RAG
对话历史
外部记忆
工具调用
但它们的目标完全一致:
让模型在推理时看到更多正确的信息。
七、智能的真正来源
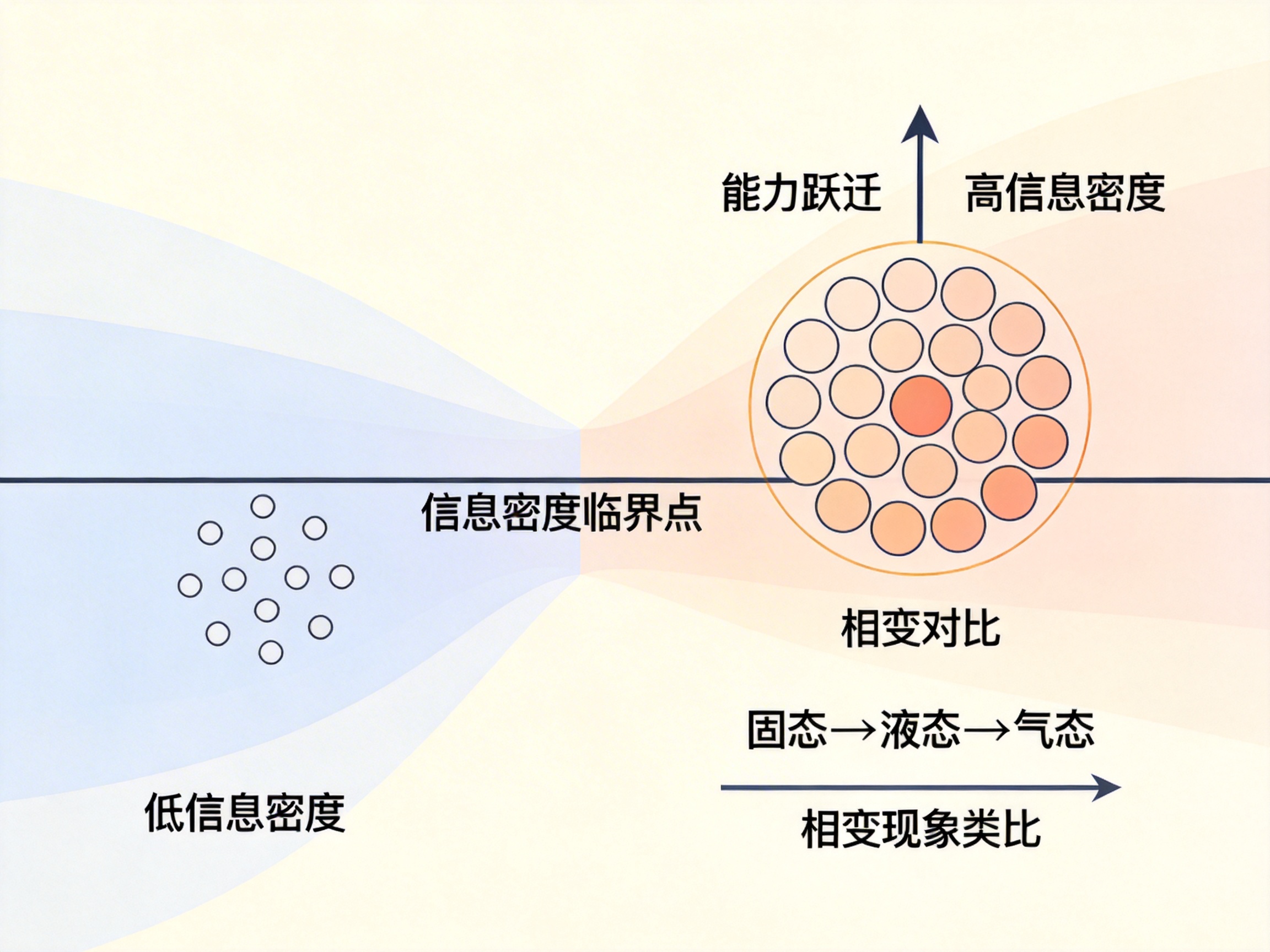
信息密度跨越临界点
当信息密度达到某个阈值时:
系统会发生能力跃迁。
这并不是模型突然“学会思考”。
而是因为:
信息量首次足以支撑复杂结构推理。
从复杂系统视角看
这是一种典型的相变现象:
水达到临界点会汽化
网络达到连接密度会形成巨型结构
同样:
当信息密度足够高时,复杂智能行为自然涌现。
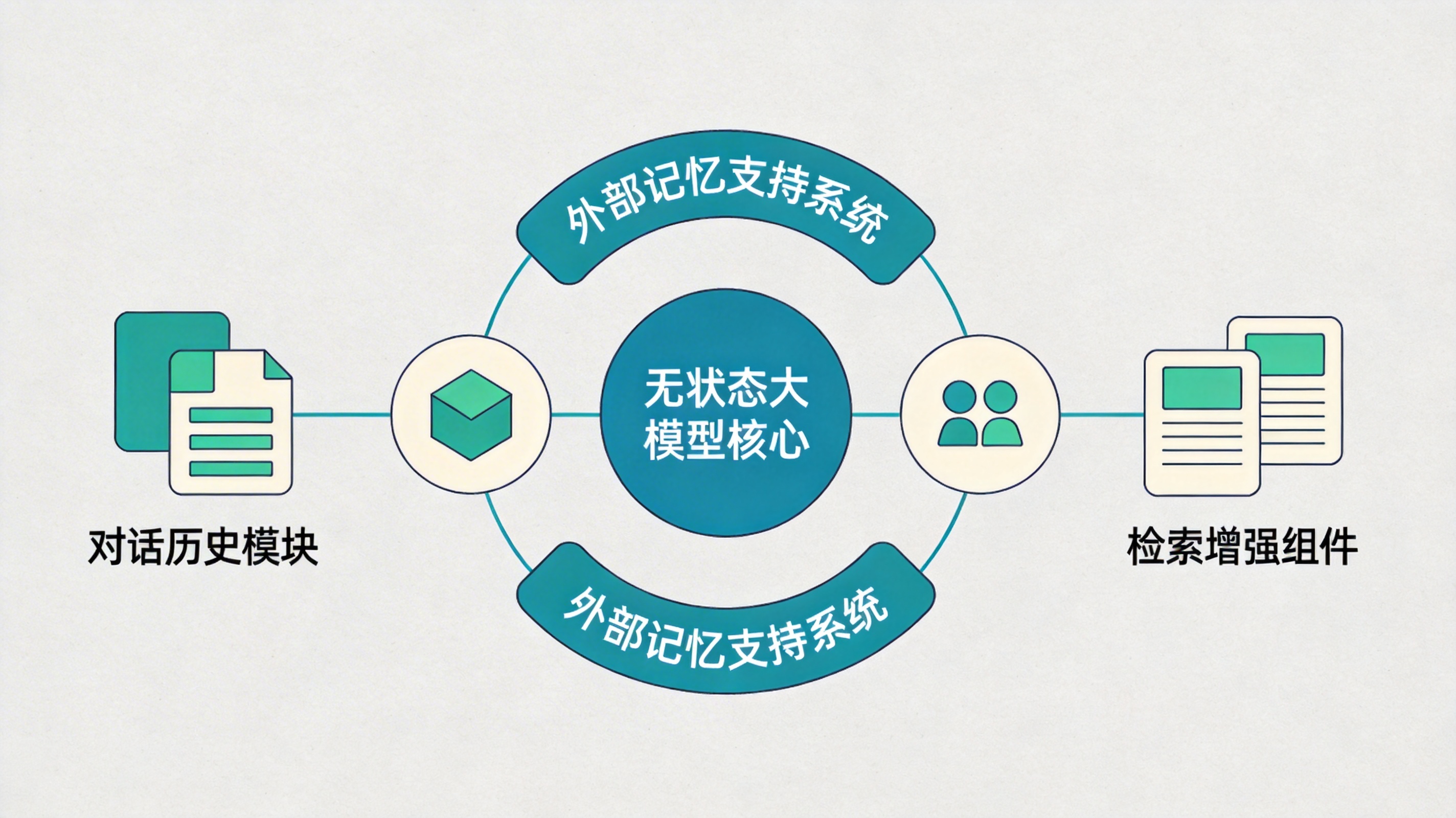
八、关于记忆的真正结论
大语言模型本质上是无状态系统:
不自动保存历史
不跨推理保留内部状态
现实中的“记忆感”来自外部系统:
对话历史重放
检索增强
参数更新
因此:
模型没有内生记忆,但可以在系统支持下表现出稳定记忆行为。
最终总结
一句话理解大模型能力本质
参数规模决定模型能“想多复杂”,
Context 决定模型能“看到多少”,
真正的智能水平,取决于推理时的信息密度。
```
来源:程序园用户自行投稿发布,如果侵权,请联系站长删除
免责声明:如果侵犯了您的权益,请联系站长,我们会及时删除侵权内容,谢谢合作!
Context
本质
AI
变强
后的
相关帖子
AI写论文真能过查重?实测6款论文AI生成工具,一键生成高质量论文,查重率超必退
从 Vibe Coding 到 AI Agent,OceanBase seekdb 打造 AI 时代毫秒级数据沙箱
你以为AI记住了你,其实没有:大模型记忆机制拆解
AI Agent 生产级记忆系统目录结构
AI辅助编程系统工程的注意事项-程序员从“农耕”走向“魔法”的时代
AI 自动编程:一句话设计高颜值博客
拒绝花哨,回归本质:19 款主流与小众浏览器硬核性能横评 (2026版)
一键把你的电脑变成 AI 助理:ClawX 实战指南(新手也能 3 分钟上手!)
智谱AI GLM-5 技术报告全面解读
AI为什么会撒谎——一个律师被ChatGPT骗了
回复
使用道具
举报
提升卡
置顶卡
沉默卡
喧嚣卡
变色卡
千斤顶
照妖镜
相关推荐
安全
AI写论文真能过查重?实测6款论文AI生成工具,一键生成高质量论文,查重率超必退
0
2
赖琳芳
2026-02-28
安全
从 Vibe Coding 到 AI Agent,OceanBase seekdb 打造 AI 时代毫秒级数据沙箱
0
102
恙髡
2026-02-28
业界
你以为AI记住了你,其实没有:大模型记忆机制拆解
0
561
事确
2026-02-28
安全
AI Agent 生产级记忆系统目录结构
0
349
郗燕岚
2026-02-28
业界
AI辅助编程系统工程的注意事项-程序员从“农耕”走向“魔法”的时代
0
543
啦迩
2026-02-28
业界
AI 自动编程:一句话设计高颜值博客
0
447
司马黛
2026-02-28
业界
拒绝花哨,回归本质:19 款主流与小众浏览器硬核性能横评 (2026版)
0
690
翁谌缜
2026-02-28
业界
一键把你的电脑变成 AI 助理:ClawX 实战指南(新手也能 3 分钟上手!)
0
386
慎气
2026-02-28
业界
智谱AI GLM-5 技术报告全面解读
0
4
班闵雨
2026-02-28
业界
AI为什么会撒谎——一个律师被ChatGPT骗了
0
313
馏栩梓
2026-03-01
高级模式
B
Color
Image
Link
Quote
Code
Smilies
您需要登录后才可以回帖
登录
|
立即注册
回复
本版积分规则
回帖并转播
回帖后跳转到最后一页
签约作者
程序园优秀签约作者
发帖
呶募妙
昨天 05:30
关注
0
粉丝关注
32
主题发布
板块介绍填写区域,请于后台编辑
财富榜{圆}
3934307807
991125
anyue1937
9994892
kk14977
6845359
4
xiangqian
638210
5
宋子
9888
6
韶又彤
9912
7
闰咄阅
9993
8
刎唇
9995
9
蓬森莉
9876
10
遗憩
10006
查看更多
今日好文热榜
313
AI为什么会撒谎——一个律师被ChatGPT骗了
266
聚合系统设计:策略模式(Strategy Pattern
962
pyside6控件记录
161
超性感的轻量级openclaw平替,我给nanobot
926
[大模型实战 07] 基于 LlamaIndex ReAct 框
933
让Agent越来越"懂你":长期记忆的原理与工
7
Python 潮流周刊#140:开发自己的 OpenClaw
310
linux开个子用户记录
86
[linux] 双蓝牙问题修复
79
Luogu P2155 [SDOI2008] 沙拉公主的困惑 题
5
上门维修人工派单耗时久,企业如何开始搭建
37
最小二乘问题详解11:基于李代数的PnP优化
640
OpenClaw 架构设计全解析
811
display: contents 详解
570
开源一个 React 股票 K 线图组件,传个股票
128
OpenCSG月度更新2026.2
532
为什么我就想要「线性历史 + Signed Commit
915
JavaParser使用指南
40
没人想看Word长篇大论!2026年产品经理要学
861
STC8G内置IRC 32KHz的试用


 提升卡
提升卡 置顶卡
置顶卡 沉默卡
沉默卡 喧嚣卡
喧嚣卡 变色卡
变色卡 千斤顶
千斤顶 照妖镜
照妖镜



