

6
|
Google最新发布的Gemma 4,正在把AI从云端"拉"到你的桌面上。不需要昂贵的服务器,不需要网络连接,在你的电脑上、在你的设备里,AI就能跑起来。 而且这次,Google还拉上了NVIDIA一起搞事情——从高性能游戏显卡RTX,到边缘计算设备Jetson Orin Nano,全面适配。 这篇文章,会让你彻底理解:为什么Gemma 4可能是我这段时间最关注的AI模型,以及——它跟你普通人有什么关系。
过去几年,AI领域有一个明显的趋势:模型越来越大,但越来越难用到。 你要用ChatGPT?得联网。你要做AI生图?得把数据传到云端。你想跑自己的AI助手?抱歉,一般人根本没有那个硬件条件。 但现在,风向变了。 开放模型正在推动新一轮设备端AI浪潮,把创新从云端扩展到日常本地设备。这意味着,AI不再是大公司、大平台的专属,而是每个人都能在手里、在桌上、在手边设备上用起来的东西。 Gemma 4,就是这个趋势里最重磅的产品之一。 2 Gemma 4 家族全解析 Gemma 4不是单个模型,而是一个完整的模型家族。这次发布包含了四个主要变体:E2B、E4B、26B、31B。 E2B和E4B:超高效边缘推理 这两个是小尺寸模型,专为超高效、低延迟的边缘推理打造。什么叫边缘推理?就是你家的路由器、你桌上的树莓派、乃至于一个只有几瓦功耗的模块,都能跑得动。 甚至在Jetson Nano这样的超小型设备上,都能实现接近零延迟的完全离线运行。 这就意味着——以前需要云计算中心才能做的事,现在在你家客厅就能完成。 26B和31B:高性能强力输出 如果你需要更强的算力,这两个大尺寸模型就是为高性能推理和开发者工作流设计的。 它们特别适合: 代理式AI任务(让AI帮你自动化工作) 代码生成和调试 复杂问题求解 多模态理解(看图、听声音、理解视频) 而且这次Google和NVIDIA的合作,让这些模型在RTX 5090甚至DGX Spark这样的个人AI超算上都能高效运行。 Gemma 4 强势发布!NVIDIA设备端AI时代来了,普通人也能用最强模型 3 全模态能力,才是真正的好东西 评价一个AI模型厉不厉害,不能只看参数大小,更要看它能做什么。 Gemma 4的全模态能力,是我觉得最惊艳的部分: 推理:复杂问题求解、数学逻辑分析,不在话下 编码:代码生成、调试、开发者工作流原生支持 视觉:对象识别、图像理解、文档智能 音频:自动语音识别,多语言支持 多语言:开箱即用支持35种语言,预训练覆盖140种语言 而且它支持交错式多模态输入——你可以在一句话里同时输入文本和图片,AI都能理解。 这意味着什么? 一个普通人,可以用它在本地做PPT、读论文、分析数据、生成代码——全程不需要联网,所有数据都在你自己设备上。 |

|

|

|

|

|


美国总统特朗普表示,他预计与伊朗的协议将很快宣布,并称该协议将为美国带来「免费石...

据央视新闻报道,当地时间 16 日美国总统特朗普表示,美国已获得一份「极具分量」的声...

美国总统特朗普表示,「我们现在与伊朗的关系非常好。」离与伊朗达成协议非常近。 如...

据美国司法部消息,美国德克萨斯州男子Robert Dunlap因策划加密货币诈骗、骗取近1000...

模型上下文协议(MCP)对智能代理人工智能(agentic AI)用户来说是一大便利,采用智...

5G浪潮下的机遇:世界万物互联5G,一个当下再也熟悉不过的新型技术名词。它以大宽带(...
在通过对多个同类样本进行分析后发现,这批恶意程序为后门病毒,其中的两大版本均是通...
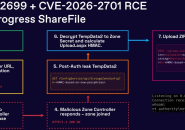
企业级安全文件传输解决方案Progress ShareFile存在两处漏洞,攻击者可将其组合利用,...





 粤ICP备2021058574号-1 |
粤ICP备2021058574号-1 |