
32
|
先从一个比喻说起 想象你们公司有一位经验极其丰富的老师傅,什么疑难杂症都能搞定,但他工资高、效率慢,每件事都要他亲自上阵,成本受不了。 于是公司安排了一个年轻人,天天跟着老师傅学。年轻人不用把老师傅几十年的经历全部重来一遍,他只需要观察老师傅怎么处理问题、怎么做判断,把这些"决策模式"学到手就行。 过一段时间,年轻人虽然没有老师傅那么全面,但对于日常 80% 的工作,已经处理得又快又好了。  这就是蒸馏。
大模型(比如 GPT-4、Claude Opus)确实厉害,但有几个现实问题:
蒸馏到底怎么做的? 传统训练一个模型,是拿"标准答案"来教它。比如一张猫的图片,标签就是"猫"——对就是对,错就是错。 但蒸馏不一样。蒸馏是拿大模型的"思考过程"来教小模型。 举个例子 假设你让大模型做一道分类题,判断一张图是猫、狗还是兔子。 标准答案是:猫。 但大模型给出的判断是这样的: 类别概率猫90%狗8%兔子2% 注意这里面的信息量。大模型不仅说了"是猫",还透露了一个重要信息:这张图跟狗也有点像,但跟兔子差远了。 这些"软标签"(soft labels)里藏着大模型对数据的深层理解——哪些类别之间容易混淆、哪些特征是相似的。 蒸馏就是让小模型不去学那个硬邦邦的标准答案"猫",而是去学大模型输出的这个概率分布。这样小模型能学到更多"隐含知识"。 核心公式(看不懂可以跳过) 蒸馏的损失函数通常是两部分的加权组合: L = α × L_soft + (1-α) × L_hardL_soft:小模型的输出和大模型的输出之间的差距(用 KL 散度衡量)L_hard:小模型的输出和真实标签之间的差距(传统的交叉熵)α:控制两者比重的参数 简单说:一边跟着老师学,一边也看看标准答案,两头兼顾。 在大语言模型时代,蒸馏变了 上面说的是经典蒸馏,是 Hinton 在 2015 年提出的方法。到了大语言模型(LLM)时代,蒸馏的玩法进化了很多。 方法一:用大模型生成训练数据 最简单粗暴的方式——让大模型回答大量问题,把这些问答对收集起来,然后用这些数据去训练小模型。 比如很多开源模型的训练过程就是这样:
方法二:蒸馏推理能力 OpenAI 的 o1、o3,DeepSeek 的 R1,这些"会思考"的模型出来之后,蒸馏又有了新方向——不光学答案,还要学"思考链"(Chain of Thought)。 具体做法是:
方法三:逐层蒸馏 让小模型不只学最终输出,还学大模型每一层的中间状态。这种方式信息保留得更多,但技术实现更复杂,通常需要大模型和小模型的架构比较接近才好做。 蒸馏的效果怎么样? 举几个真实案例:
蒸馏的局限性 蒸馏也有天花板:
很多人会把蒸馏和微调搞混,它们确实有重叠,但侧重点不同: 维度微调(Fine-tuning)蒸馏(Distillation)数据来源人工标注的数据大模型生成的数据/输出目标让模型适应特定任务让小模型学到大模型的能力模型大小通常不变通常会变小核心价值任务适配能力压缩 实际操作中,蒸馏和微调经常一起用——先蒸馏得到一个不错的小模型,再用少量高质量数据微调到具体任务上。 番外:X 上的"人肉蒸馏" 讲完技术上的蒸馏,聊一个有意思的现象——最近 X(Twitter)上出现了大量"蒸馏名人"的账号。 他们干的事情是:把 Naval Ravikant、Elon Musk、Sam Altman、Paul Graham 等人的推文、播客、演讲,提炼成线程、金句卡片、总结帖,然后发出来涨粉。 你仔细想想,这和 AI 蒸馏的逻辑完全一样:
这件事有价值吗? 有。确实降低了好内容的获取门槛,有些蒸馏者做得不错,加了自己的理解和结构化整理,附加价值是实实在在的。 但问题也很明显 第一,丢失了最关键的东西——推理过程。 和 AI 蒸馏一模一样。只学"结论"不学"思考链",是最大的信息损耗。Naval 说"不要为了钱出卖时间",蒸馏号把这句话搬过来,读者记住了金句,却完全不理解 Naval 是在什么语境下、经过什么推理得出这个结论的。金句一旦脱离了上下文,就从智慧变成了鸡汤。 第二,蒸馏者自身的"参数量"不够。 一个没有创业经验的人去蒸馏 Elon Musk 的商业智慧,就像用一个 1B 参数的模型去蒸馏 400B 参数的模型——容量不够,理解就会走形。断章取义、过度简化、甚至完全曲解原意的情况非常常见。 第三,制造了一种"已经懂了"的幻觉。 读了十条蒸馏帖,感觉自己把 Naval 的思想体系掌握了,实际上只是记住了几句没有根基的漂亮话。这比不知道更危险,因为它关闭了你继续深挖的动力。 第四,劣币驱逐良币。 蒸馏帖流量大、制作成本低,导致真正做原创思考的人反而没什么人看。X 上的信息生态越来越像一个"金句回收站"。 和 AI 蒸馏最大的区别 AI 蒸馏有明确的评估指标——准确率、推理速度、benchmark 分数,蒸馏质量一测便知。 但人肉蒸馏没有。读者无法判断蒸馏的质量,因为他们本来就没看过原版。这就导致蒸馏质量完全不可控,市场也无法自然筛选——写得最"像回事"的蒸馏帖,反而可能是歪曲最严重的。 给读者的建议 如果你是蒸馏帖的消费者,记住一条:看蒸馏帖不如看原版,就像用小模型不如直接用大模型——前提是你付得起那个成本。 如果付不起,至少要意识到你看到的是压缩版,而非全貌。 |

|

|

|

|

|


美国总统特朗普表示,他预计与伊朗的协议将很快宣布,并称该协议将为美国带来「免费石...

据央视新闻报道,当地时间 16 日美国总统特朗普表示,美国已获得一份「极具分量」的声...

美国总统特朗普表示,「我们现在与伊朗的关系非常好。」离与伊朗达成协议非常近。 如...

据美国司法部消息,美国德克萨斯州男子Robert Dunlap因策划加密货币诈骗、骗取近1000...

模型上下文协议(MCP)对智能代理人工智能(agentic AI)用户来说是一大便利,采用智...

5G浪潮下的机遇:世界万物互联5G,一个当下再也熟悉不过的新型技术名词。它以大宽带(...
在通过对多个同类样本进行分析后发现,这批恶意程序为后门病毒,其中的两大版本均是通...
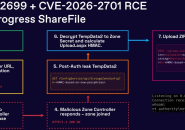
企业级安全文件传输解决方案Progress ShareFile存在两处漏洞,攻击者可将其组合利用,...





 粤ICP备2021058574号-1 |
粤ICP备2021058574号-1 |