
14
|
项目地址:https://github.com/yaklang/hack-skills  仓库 Banner hack-skills 不是教你怎么用某款漏洞扫描工具,也不是又一个 payload 字典。它的定位更底层一些——给 AI 提供一套结构化的安全知识,让 Agent 在面对真实目标时,能像一个有经验的测试员那样思考和行动。 设计思路:不是字典,是"路由表" 跑一个 SQLi payload 列表谁都会,但测试员真正的价值在于知道什么时候该测什么。 hack-skills 采用三层结构来解决这个问题: Master Entry(总入口)└── Category Entries(六个类别入口) └── Deep Topic Skills(100+ 专题技能) 每个技能文件固定放在 skills/{semantic-identifier}/SKILL.md,格式统一、可被 Agent 检索。 这种设计背后有个很具体的考虑:LLM 在做安全测试时,最容易犯的错不是"知识不够",而是面对一个新目标不知道先做什么、测到一半没有路由到合适的攻击面。所以主入口 (skills/hack/SKILL.md) 的核心功能其实是一张"路由表"。 [td]
Agent 先用这张表确定当前场景最相关的攻击面,再按需加载对应的深层专题技能——而不是一次性把所有 payload 都倒进来。 覆盖范围:14 个安全领域,100+ 专题 说技能数量没什么意义,列几个具体的专题更直观: Web 与 API 安全(高频) 覆盖了 XSS、SQLi、SSRF、SSTI、XXE、命令注入、反序列化、JNDI 注入、CRLF 注入、HTTP Request Smuggling、Prototype Pollution、HTTP 参数污染……基本把 OWASP Top 10 及延伸场景都跑了一遍。 认证与授权 JWT/OAuth 攻击、SAML SSO 断言伪造、IDOR/BOLA、OAuth/OIDC 错误配置——这几个在实际漏洞赏金里高频出现,且经常被扫描器漏掉的点都在里面。 基础设施与提权
二进制与逆向 Stack Overflow + ROP、堆利用、格式字符串、内核漏洞利用、V8 浏览器漏洞利用、沙箱逃逸、反调试技术、符号执行。 密码学攻击 RSA 攻击(共模、低公钥指数、Coppersmith 等)、对称加密缺陷、格密码分析、哈希攻击。 新兴领域 LLM Prompt Injection、AI/ML 安全、智能合约安全与 DeFi 攻击模式也有专题覆盖。 知识来源与"蒸馏"原则 仓库 README 里明确列了参考来源:
但这里有个关键区别:它不是上面这些资料的镜像,而是做了二次加工。 具体来说,把大量payload列表、字典、原始案例,压缩成"可路由、可组合、可审查"的安全技能条目。砍掉了直接的字典复制,保留了分类框架、边界条件描述和攻击链路逻辑。 这个取舍是为了Agent工作效率考虑的——LLM上下文窗口有限,一次性把PayloadsAllTheThings全文丢进去反而会降低推理质量,不如给它一个"先想清楚在哪个方向,再按需取用"的框架。 快速上手 方式一:通过skills CLI安装 npx skills add yaklang/hack-skills 安装后,直接用hack这个frontmatter name在支持的工具里引用主入口。 方式二:直接拉取主入口SKILL文件 curl-fsSL https://raw.githubusercontent.co...kills/hack/SKILL.md 方式三:本地克隆作为知识库使用 git clone https://github.com/yaklang/hack-skills.git cd hack-skills 推荐的阅读顺序:主入口→六个类别入口→按需深入专题。别一上来就直接看深层的专题文件,会没有上下文。 六个类别入口分别是: recon-for-sec:侦察与方法论 api-sec:API安全 auth-sec:认证与授权 injection-checking:注入攻击 file-access-vuln:文件与路径攻击 business-logic-vuln:业务逻辑与会话 主入口的raw URL:https://raw.githubusercontent.co...kills/hack/SKILL.md 几个实际使用场景 场景一:漏洞赏金新目标 接手一个新目标,拿出主入口hack让Agent加载,按Step 1(Recon上下文确认)→Step 2(按现象路由)→Step 3(优先测试顺序)走一遍。比让Agent自由发挥要稳定得多,不会跳过一些高价值但不在"常识"里的测试点,比如HTTP/2特有攻击面或CSP绕过。 场景二:CTF比赛中的Pwn/Crypto题 Pwn方向,从stack-overflow-and-rop→heap-exploitation→kernel-exploitation依次展开;Crypto方向,从rsa-attack-techniques或lattice-crypto-attacks进入。每个专题里都有具体的攻击思路和边界条件,不是泛泛的概念描述。 场景三:让Agent做初步Web渗透自动化 把hack主入口加上xss-cross-site-scripting、sqli-sql-injection、ssrf-server-side-request-forgery一起喂给Agent,让它配合Burp/nuclei做初步的测试点识别。Agent会参考路由逻辑决定优先级,而不是对着每个参数无脑扫一遍。 场景四:Active Directory渗透路径规划 内网里拿到低权限,用active-directory-kerberos-attacks+ntlm-relay-coercion+active-directory-certificate-services三个专题串联,帮Agent梳理从低权限到域管的可能路径。AD CS的ESC系列漏洞路径在里面有明确覆盖。 和直接让ChatGPT写payload有什么区别 这个问题值得单说一下。 直接问LLM"帮我测试SSRF",它会给你一个通用答案,基于训练数据里的平均水平。而训练数据里,很多边界条件(比如DNS rebinding绕过SSRF防护、HTTP/2 multiplexing攻击面)的覆盖是稀疏的,容易被忽略。 hack-skills的思路是给Agent一套结构化的方法论上下文,而不是单纯依赖模型权重里的隐式知识。这在面对不常见的漏洞类型或者需要组合多个技术点的场景时,差距比较明显。 另外,安全测试里有很多"对的顺序"问题——同样的技术,测试顺序不对就错过了。这种顺序性的判断,放在结构化的技能文件里比让模型自己推断要可靠。 |

|

|

|

|

|

该工具专为运维和安全检查和学习研究设计,类似于软件商城,可以实现工具下载、更新,...

@outsource_在4月5日发布了越狱版Gemma-4-31B 越狱无限制非常适合网安创业团队、公司...

项目地址:https://github.com/yaklang/hack-skills 仓库 Banner hack-skills 不是教...
CyberStrikeAI 是一个用 Go 写的 AI 原生安全测试平台。你用自然语言告诉它要测什么,...

一位韩国知名黑客近日宣布,他已成功攻克PS5和PS4的系统内核,发现了一个索尼官方至今...

据EclecticIQ威胁分析师披露,俄罗斯军事网络间谍组织Sandworm正在针对乌克兰的Window...
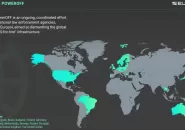
在 “PowerOFF 行动” 最新阶段的国际执法行动中,已通过电子邮件和信件对超过 7.5 万...

一款名为ZionSiphon的新型恶意软件专为运营技术环境打造,将目标锁定在水处理和海水淡...




 粤ICP备2021058574号-1 |
粤ICP备2021058574号-1 |