后彼
2025-6-4 21:46:50
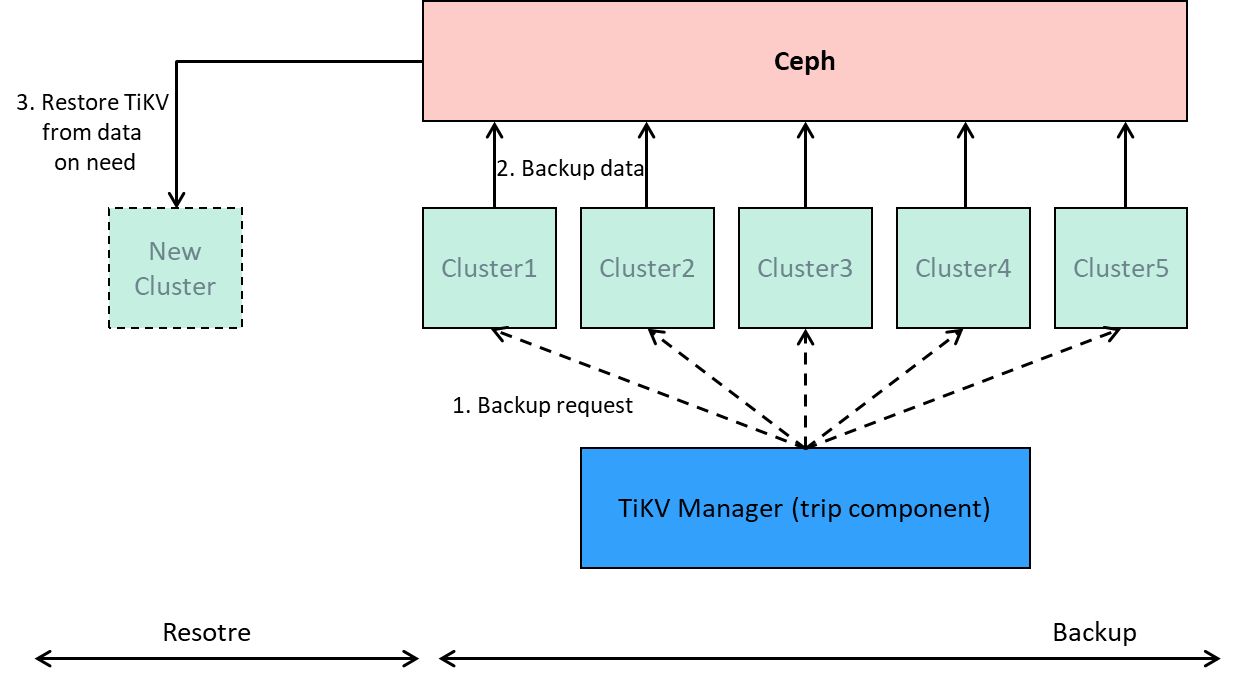
在过去两年多的时间里,随着 AI 大模型的快速发展,JuiceFS 在携程内部得到了越来越多 AI 用户的关注。目前,携程通过 JuiceFS 管理着 10PB 数据规模,为 AI 训练等多个场景提供存储服务。01 JuiceFS 在携程的应用:从冷存到 AI 场景 02 JuiceFS 部署架构 & 关键能力 TiKV & PD 作为元数据引擎 :TiKV 支持分布式架构和事务处理,具备出色的性能。通过跨 IDC 部署,确保系统的高可用性。Ali OSS 作为存储底座 :结合专线网络提供大带宽传输能力。同时,OSS 的自动转冷功能使得系统在成本控制上具有优势,性价比高。JuiceFS 客户端的定制化 :对 JuiceFS 客户端 进行了针对性修改,特别是在内部管理功能上,例如自助服务、计费系统、控制限速等。我们还进行了优化,以便用户在 Kubernetes (k8s) 环境中能够方便地使用。关键能力 1:多租户权限管理与计费 计费原理 费用异常:存储泄露 我们通过使用 OSS 清单对数据进行聚合,发现 JuiceFS 统计的用量远低于 OSS 统计的用量。这导致了用户在 JuiceFS 中的存储空间使用量被低估,从而使得 OSS 存储空间的费用被错误地分摊给其他用户,进而导致其他用户的单价上升 。功能禁用 禁用回收站 :回收站功能在很多用户场景下并不需要开启。回收站是后台任务,需要额外的资源进行清理,尤其是在使用 TiKV(如 RocksDB 数据库)的情况下,回收站会对数据库性能造成一定压力,尤其在出现突发的大规模删除时。因此,我们选择不启用回收站功能。禁用备份元数据(BackupMeta)功能 :JuiceFS 提供了元数据备份功能,但在数据量较大时,逻辑备份速度较慢,无法满足我们的需求。为了提高备份效率,我们更倾向于使用 TiKV 提供的官方备份工具来进行数据库备份,这样可以更好地支持大规模数据的备份需求。关键能力 2:日志收集与管理,提高排障效率 关键能力 3:监控 性能相关指标:包括 CPU、内存使用情况以及热点读写。 PD(相关指标:重点监控 Region leader 分布与调度情况。 GC(垃圾回收)相关指标:包括 GC 时间和 MVCC 删除等信息。 关键能力 4:元数据备份 最终,我们采用了 TiDB 的全量快照备份方案,每日进行定时备份 。虽然可以成功备份数据,但在恢复时出现了错误。 在备份过程中,TiKV 持续尝试执行备份操作,且无法停止。 目前,在我们的最大集群扩展后的生产环境中,能够在 20 分钟内完成全量备份。备份任务基本上会在每天定时执行,并通过监控实时查看备份状态 。由于 JuiceFS 服务全天没有明显低谷,我们选择在白天对 TiKV 进行备份。03 生产环境排障案例 案例 1:TiKV MVCC (Multi-Version Concurrency Control) 堆积 奇怪的是,TiKV 的 CPU 使用率和 QPS 并未发生明显变化。进一步分析日志后,发现大量与 region 相关的报错,这些错误是由于 MVCC(多版本并发控制) 堆积引起的 。MVCC 堆积后,region 内的旧版本数据不断累积,导致 region 无法正常分割,从而阻碍了硬盘空间的及时回收。频繁更新同一 chunk 会使 TiKV 无法及时回收过期的版本,从而迅速消耗存储资源,最终导致 MVCC 堆积 。随着这些未回收的旧版本不断积累,TiKV 的存储压力逐渐增加,可能会导致性能下降,甚至引发磁盘空间不足等问题。JuiceFS :由于 chunk 记录的 slice 数量不断增多,JuiceFS 需要更多时间来恢复完整的文件视图。当 slice 数量过多时,JuiceFS 会暂停写入,并强制执行数据压缩(compaction)操作。 TiKV:频繁写入版本会增加 RocksDB 中存储的数据量,导致 LSM 树的读性能下降,从而影响 TiKV 的整体性能。 案例 2:大量容器同时扫盘打爆 TiKV 消除 updatedb 的影响 :通过使用 ConfigMap 将 /etc/updatedb.conf 挂载到用户 Pod 中,覆盖镜像自带的配置,并在配置中禁止扫描 JuiceFS 挂载点。限流元数据操作 :为了防止用户不经意间的行为影响 TiKV 集群的性能,我们修改了 JuiceFS 和 TiKV 相关代码,在元数据部分添加了限流机制,避免 TiKV 因过多文件查找请求而过载。进一步限流代码 :尽管之前对 OSS 带宽进行了限流,但问题仍未完全解决。因此,我们进一步添加了针对元数据操作的限流代码,特别是针对 TiKV 的元数据操作,从而缓解了 TiKV 集群服务质量下降的问题。案例 3:JuiceFS client OOM 04 JuiceFS 的成本优势:十分之一极速 NAS 通过将 JuiceFS 与 OSS 结合使用,我们实现了一个分布式文件系统方案,能够在大多数业务场景中提供与极速 NAS 相同的功能和接近的性能,而成本仅为极速 NAS 的十分之一 。 这一成本优势是 JuiceFS 方案的最大魅力之一,它能够显著降低我们的运营成本。Q&A 大模型对于存储的主要需求是什么,还是只关注性价比 ?从对象存储拉取数据慢,有什么建议 ?TiKV元数据规模大概能支撑到多大的量?数据量大的场景,元数据是不是成为瓶颈 ?
相关推荐















 提升卡
提升卡 置顶卡
置顶卡 沉默卡
沉默卡 喧嚣卡
喧嚣卡 变色卡
变色卡 千斤顶
千斤顶 照妖镜
照妖镜



