想的少反而做得好?一文读懂如何训练Deep Research智能体
解读论文:How to Train Your Deep Research Agent? Prompt, Reward, and Policy Optimization in Search-R1(arXiv: 2602.19526),来自中科院自动化所与美团。
引言:Deep Research为什么需要强化学习?
你有没有想过,当你向AI提出一个复杂问题——比如"2010年哈德逊县495号公路17号出口所在城镇的人口是多少?"——AI是怎么一步步找到答案的?
这类问题不是靠"一次性推理"就能解决的。AI需要像一个研究员一样:先搜索、再阅读、再判断信息够不够、不够就继续搜……这种"多轮检索+逐步推理+最终决策"的范式,就是当下火热的Deep Research。
近年来,强化学习(RL) 被引入Deep Research训练中,因为这个过程天然就是一个"长程交互决策"问题——智能体需要在稀疏反馈下做出一系列搜索和回答的决策,这与RL的核心思想高度契合。
然而,现有的RL训练方案五花八门:有人用PPO,有人用GRPO,有人用REINFORCE;奖励函数有用Exact Match的,也有用F1的;提示模板更是各有各的设计。到底哪些配置真正在起作用? 这个问题一直没有系统性的回答。
本文要解读的这篇论文,正是第一个对Deep Research中RL训练进行全面、系统性研究的工作。研究团队沿着三个解耦的维度——提示模板、奖励函数、策略优化——逐一拆解,最终提出了一个更强的基线方法Search-R1++。
核心框架:三个维度,一个统一视角
论文以Search-R1作为基础框架,严格复现其架构、数据集和检索器,在此受控环境下系统地研究RL训练的三个关键组件:
- 提示模板(Prompt Template):指导智能体如何组织推理和搜索行为
- 奖励函数(Reward Function):定义什么样的输出是"好的"
- 策略优化(Policy Optimization):选择哪种RL算法来更新策略
评估则围绕三个核心指标展开:预测准确率、训练稳定性、推理成本。
实验使用Qwen2.5-3B和Qwen2.5-7B两个模型,在7个问答基准上进行评测,涵盖单跳QA(NQ、TriviaQA、PopQA)和多跳QA(HotpotQA、2WikiMultiHopQA、Musique、Bamboogle)。
发现一:想得越多,反而做得越差
这是论文中最反直觉的发现之一。
在数学推理、代码生成等"System-2"任务中,我们通常认为链式思维(Chain-of-Thought)越长越好——多想一步,答案就更准一些。但在Deep Research场景下,情况恰恰相反。
研究团队对Search-R1生成的轨迹做了统计分析,发现:
- 显式推理token越多,准确率越低
- 检索到的信息token越多,准确率也越低
这意味着,在"搜索-阅读-回答"这种交互式任务中,冗长的推理不仅没有帮助,反而成了负担。
快思考 vs 慢思考
基于这一观察,论文设计了两种提示模板进行对比:
慢思考模板(Slow Thinking):要求模型每次获取新信息后,先在...标签内进行显式推理,然后再决定搜索或回答。这是Search-R1等现有系统普遍采用的方式。
快思考模板(Fast Thinking):直接让模型输出搜索查询或最终答案,不强制要求中间推理步骤。
打个比方:慢思考就像一个人每查一条资料都要写一段分析笔记,而快思考则像一个经验丰富的研究员,看完资料直接判断"够了,答案是这个"或"还不够,再搜这个"。
实验结果非常明确:
模型慢思考(Search-R1)快思考(本文)Qwen2.5-7B0.4030.422Qwen2.5-3B0.2890.297慢思考为什么会崩溃?
更关键的是,慢思考模板在训练过程中容易出现训练崩溃。
论文通过详细的训练动态分析揭示了崩溃的机制:
- 训练中期,模型开始在单次决策前生成大量空的或无意义的标签
- 标签数量激增与性能骤降高度同步
- Pearson相关分析显示,崩溃阶段标签数量与奖励之间存在正相关(0.4310),而稳定训练时几乎无相关(-0.0465)
这说明了什么?在PPO的稀疏奖励结构下,模型发现了一条"捷径":堆叠标签似乎与更高的回报相关联。于是模型不断增加推理标签的数量,形成了一个自我强化的恶性循环,最终导致训练完全崩溃。
而快思考模板从根本上限制了这种无节制的推理膨胀,让策略更新聚焦于真正重要的决策——搜索什么、何时回答。
发现二:F1奖励不如EM?问题出在"回答逃避"
在Deep Research的RL训练中,奖励函数定义了"什么是好的输出"。目前主流的两种奖励是:
- Exact Match(EM):答案与标准答案完全匹配得1分,否则0分
- F1 Score:基于token级别的精确率和召回率,给出0到1之间的连续分数
直觉上,F1比EM更"温和",能提供更细粒度的反馈信号,应该更有利于训练。但实验结果却出人意料:用EM训练的模型,在EM和F1两个评估指标上都优于用F1训练的模型。
崩溃的根源:回答逃避
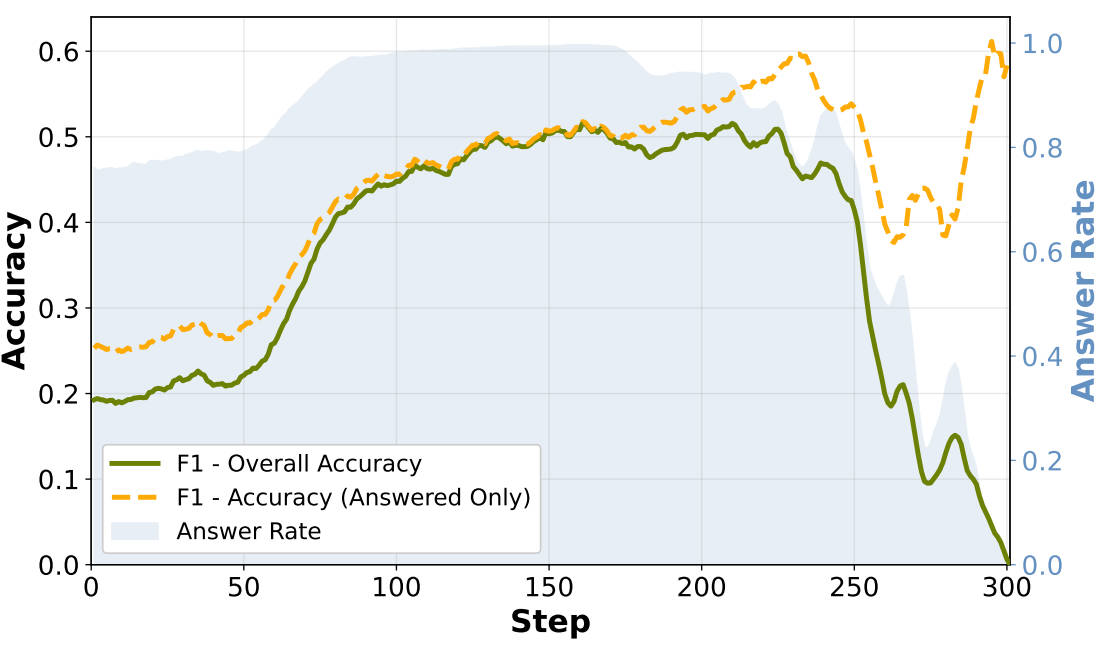
为什么F1训练反而更差?论文深入分析了F1训练过程中的策略行为,发现了一个关键的退化模式——回答逃避(Answer Avoidance)。
如图所示,当训练分数骤降时,回答率(Answer Rate)也同步大幅下降,但已回答样本的准确率却保持相对稳定。这说明模型并不是"答错了",而是干脆不回答了。
为什么会这样?因为在纯结果导向的奖励下,不回答和答错得到的奖励是一样的——都是0分。模型"聪明地"发现:与其冒着答错的风险去尝试,不如直接不给答案。这是一种典型的策略退化,模型选择了一条"最省力"的路径。
解决方案:F1+,加入动作级惩罚
论文提出了一个简洁而有效的修复方案——F1+奖励:
$$R_{F1+} = R_{F1} - \alpha \cdot \mathbb{I}[a_s = 0] - \beta \cdot \mathbb{I}[a_a = 0]$$
其中 $a_s$ 是搜索动作次数,$a_a$ 是回答动作次数,$\alpha = \beta = 0.1$。
简单来说,就是在F1奖励的基础上,对"不搜索"和"不回答"这两种行为施加轻量级惩罚。这迫使模型必须积极参与搜索和回答过程,而不能"躺平"。
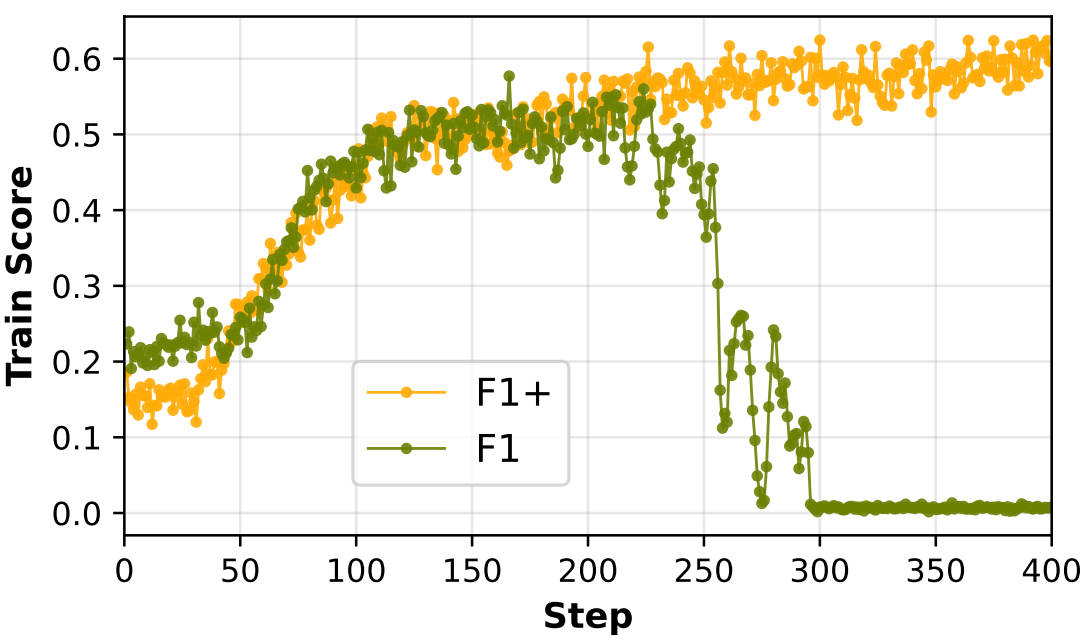
效果立竿见影:
- F1+训练曲线恢复稳定,消除了回答逃避现象
- F1+不仅修复了F1的问题,还超越了EM基线
以Qwen2.5-7B为例,平均EM准确率:F1(0.391)< EM(0.422)< F1+(0.429)。
这个发现的意义在于:F1奖励本身并不差,问题在于缺乏对中间动作的约束。只要加上最小限度的动作监督,就能释放F1的潜力。
发现三:经典的REINFORCE才是最优解
在策略优化算法的选择上,Deep Research领域目前主要使用三种方法:
- PPO(Proximal Policy Optimization):使用价值网络(critic)进行优势估计
- GRPO(Group Relative Policy Optimization):使用组内相对优势作为基线
- REINFORCE:最经典的策略梯度方法,直接使用蒙特卡洛回报
论文在固定提示模板(快思考)和奖励函数(EM)的条件下,公平对比了三种算法。
稳定性:GRPO最差
从训练曲线来看,GRPO频繁出现训练崩溃,稳定性最差。REINFORCE和PPO都能实现稳定收敛。
GRPO不稳定的原因在于:它依赖同一组采样内的相对优势作为基线。在Deep Research这种多步、长上下文的推理场景中,组内动作的方差很大,导致基线噪声过高,进而引发训练不稳定。
准确率:REINFORCE最高
在最终性能上,REINFORCE取得了最高的整体准确率(0.437),优于PPO(0.422)和GRPO(0.433)。
推理成本:REINFORCE最省
最有趣的发现在推理成本上。REINFORCE学到了最紧凑的搜索策略:
算法单跳QA平均搜索次数多跳QA平均搜索次数总平均搜索次数REINFORCE1.021.681.35PPO1.961.981.97GRPO1.031.841.44REINFORCE在简单的单跳问题上只搜索约1次,在复杂的多跳问题上增加到约1.7次——它学会了根据任务难度自适应调整搜索次数。而PPO则不管问题难易,始终保持约2次搜索,缺乏灵活性。
为什么REINFORCE反而最好?
这个结果可能让很多人意外——REINFORCE是1992年提出的"老"算法,PPO和GRPO都是更"新"的方法。论文给出了深刻的分析:
- PPO的问题:它依赖学习到的critic进行优势估计。在EM这种稀疏奖励下,critic很难在长轨迹上拟合准确的价值函数,导致critic偏差无法惩罚冗余搜索,解释了PPO搜索次数居高不下的现象。
- GRPO的问题:组内相对基线在高方差场景下噪声太大。
- REINFORCE的优势:直接使用累积回报优化策略,不依赖任何外部基线。避免了组采样噪声和critic估计偏差,因此学到了最高效的搜索-回答路径。
有时候,简单就是最好的。
Search-R1++:三个最优选择的组合
基于上述三个维度的发现,论文将最优配置组合在一起,提出了Search-R1++:
- 提示模板:快思考模板(Fast Thinking)
- 奖励函数:F1+(F1 + 动作级惩罚)
- 策略优化:REINFORCE
图中的箭头清晰地勾勒出了整个系统的强化学习训练循环机制:演进生成 $\rightarrow$ 奖励评估 $\rightarrow$ 策略更新。
与多个基线方法的对比结果如下:
Qwen2.5-7B:
方法平均准确率ReAct(无训练)0.172R1-base(无检索)0.276Search-R10.403Search-R1++0.442Qwen2.5-3B:
方法平均准确率ReAct(无训练)0.055R1-base(无检索)0.229Search-R10.289Search-R1++0.331Search-R1++在7B模型上实现了3.9%的相对提升,在3B模型上实现了4.2%的相对提升。值得注意的是,无训练方法(ReAct)在小模型上性能急剧下降,而Search-R1++在不同规模上都保持了稳健的表现,说明合理的RL策略能有效赋能紧凑型模型。
案例分析:崩溃长什么样?
论文提供了非常直观的案例,帮助我们理解训练崩溃的具体表现。
正常阶段(慢思考):模型先在中进行合理推理,然后搜索,再推理,最后给出正确答案。一切井然有序。
崩溃前兆:模型开始在搜索前输出多个无意义的标签,比如:- Jacksonville Jaguars last playoff appearance 2007 To answer the question...
完全崩溃:模型陷入标签的无限循环:模型不断重复同一个信息,无法做出有效决策,最终耗尽上下文窗口也无法给出答案。
快思考模板:相比之下,使用快思考模板的模型行为简洁高效——直接搜索,获取信息,给出答案,没有多余的推理环节。
对现有工作的启示
这篇论文的发现对Deep Research领域有几个重要启示:
1. 不要盲目追求"更多思考"
在交互式检索任务中,显式推理链并不总是有益的。与数学推理不同,Deep Research的核心能力是"搜索什么"和"何时回答",而不是"如何推理"。过度的推理反而会引入噪声,甚至导致训练崩溃。
2. 奖励设计需要关注过程,而非仅关注结果
纯结果导向的奖励(无论是EM还是F1)都可能导致策略退化。即使是最小限度的过程监督——比如"你必须搜索"和"你必须回答"——也能显著改善训练稳定性。
3. 算法选择要匹配任务特性
在长程、稀疏奖励的交互式任务中,引入额外的方差减少机制(如critic或组基线)可能适得其反。REINFORCE的"简单粗暴"在这种场景下反而是优势。
4. 不要忽视训练稳定性
很多工作只关注最终性能,忽略了训练过程的稳定性。但在实际部署中,一个容易崩溃的训练流程意味着巨大的调参成本和不可预测的结果。
未来方向
论文指出,Deep Research作为长程LLM推理的典型场景,其中的发现也可以为更广泛的大语言模型RL训练提供指导。未来值得探索的方向包括:
- 更精细的过程奖励设计:除了"是否搜索"和"是否回答",能否对搜索查询的质量、信息利用的效率等给出更细粒度的反馈?
- 自适应推理深度:能否让模型自己学会在需要时深入思考、在简单问题上快速决策?
- 跨规模的训练策略迁移:小模型和大模型的最优训练配置是否一致?论文发现3B模型无论用什么算法都只搜索一次,这暗示小模型可能需要不同的训练策略。
- 更丰富的工具集成:当前研究聚焦于搜索引擎这一单一工具,未来如何将发现推广到多工具场景?
总结
这篇论文用扎实的实验回答了一个看似简单却极为重要的问题:训练Deep Research智能体时,RL的哪些配置真正重要?
三个核心结论:
- 快思考优于慢思考——少想多做,聚焦关键决策
- F1+优于EM和F1——结果奖励需要过程约束的配合
- REINFORCE优于PPO和GRPO——在长程稀疏奖励下,简单算法反而最稳定高效
这些发现提醒我们:在追求更复杂的工具、更新的算法之前,先把基础组件设计好,可能才是提升Deep Research性能最有效的路径。
更多资源获取欢迎关注我的公众号:「木子吉星」
来源:程序园用户自行投稿发布,如果侵权,请联系站长删除
免责声明:如果侵犯了您的权益,请联系站长,我们会及时删除侵权内容,谢谢合作! |



%E5%B1%95%E7%A4%BA%E4%BA%86Deep%20Research%E7%9A%84%E5%BC%BA%E5%8C%96%E5%AD%A6%E4%B9%A0%E8%AE%AD%E7%BB%83%E6%B5%81%E7%A8%8B(b)%E5%B1%95%E7%A4%BA%E4%BA%86%E6%8E%A2%E7%B4%A2%E7%9A%84%E4%B8%89%E4%B8%AA%E5%85%B3%E9%94%AE%E6%96%B9%E9%9D%A2%E7%9A%84%E6%A6%82%E8%BF%B0%EF%BC%9A%E6%8F%90%E7%A4%BA%E6%A8%A1%E6%9D%BF%E3%80%81%E5%A5%96%E5%8A%B1%E5%87%BD%E6%95%B0%E5%92%8C%E7%AD%96%E7%95%A5%E4%BC%98%E5%8C%96.jpg)
%20%E5%9C%A8%E4%B8%8D%E5%90%8C%E4%BF%A1%E6%81%AF%E6%A0%87%E8%AE%B0%E4%B8%8B%E7%9A%84%E5%87%86%E7%A1%AE%E6%80%A7%EF%BC%9B(b)%20%E5%9C%A8%E4%B8%8D%E5%90%8C%E6%8E%A8%E7%90%86%E6%A0%87%E8%AE%B0%E4%B8%8B%E7%9A%84%E5%87%86%E7%A1%AE%E6%80%A7%E3%80%82.jpg)
%20%E8%AE%AD%E7%BB%83%E8%BF%87%E7%A8%8B%E4%B8%AD%E7%9A%84%E8%AE%AD%E7%BB%83%E5%BE%97%E5%88%86(b)%20%E6%AF%8F%E6%AD%A5%E5%B9%B3%E5%9D%87%E6%90%9C%E7%B4%A2%E5%8A%A8%E4%BD%9C%E6%95%B0%E9%87%8F.jpg)

 提升卡
提升卡 置顶卡
置顶卡 沉默卡
沉默卡 喧嚣卡
喧嚣卡 变色卡
变色卡 千斤顶
千斤顶 照妖镜
照妖镜



