LSM-Tree 日志结构合并树
LSM-Tree(Log-Structured Merge-Tree,日志结构合并树)是一种分层、有序、面向磁盘的数据结构,其核心思想是充分利用磁盘的顺序写性能远高于随机写性能的特性,通过将随机写转换为批量顺序写来优化写入效率。这种结构最初源于Google的BigTable论文,广泛应用于写多读少的场景,如NoSQL数据库。
LSM-Tree 的基本定义
LSM-Tree 不是一种严格固定的实现,而是一种设计思想。它将数据组织成多层结构(Levels),其中:
- Level 0:位于内存中,通常使用有序的数据结构如跳表(Skip List)或红黑树(Red-Black Tree),存储最近的写入操作。
- Level 1 到 Level n:位于磁盘上,每层由多个有序的文件(SSTable,Sorted String Table)组成,这些文件按键(Key)排序。
- 每一层都有大小阈值,当达到阈值时,会触发合并(Compaction)操作,将数据向下层合并。
- 数据更新不进行原地修改,而是采用追加写的方式,旧数据通过墓碑标记(Tombstone)或版本控制来处理。
LSM-Tree 的整体结构类似于一个“森林”,跨越内存和磁盘,确保数据在每一层内有序,从而支持高效的范围查询。
LSM-Tree 的工作原理
1. 写入过程
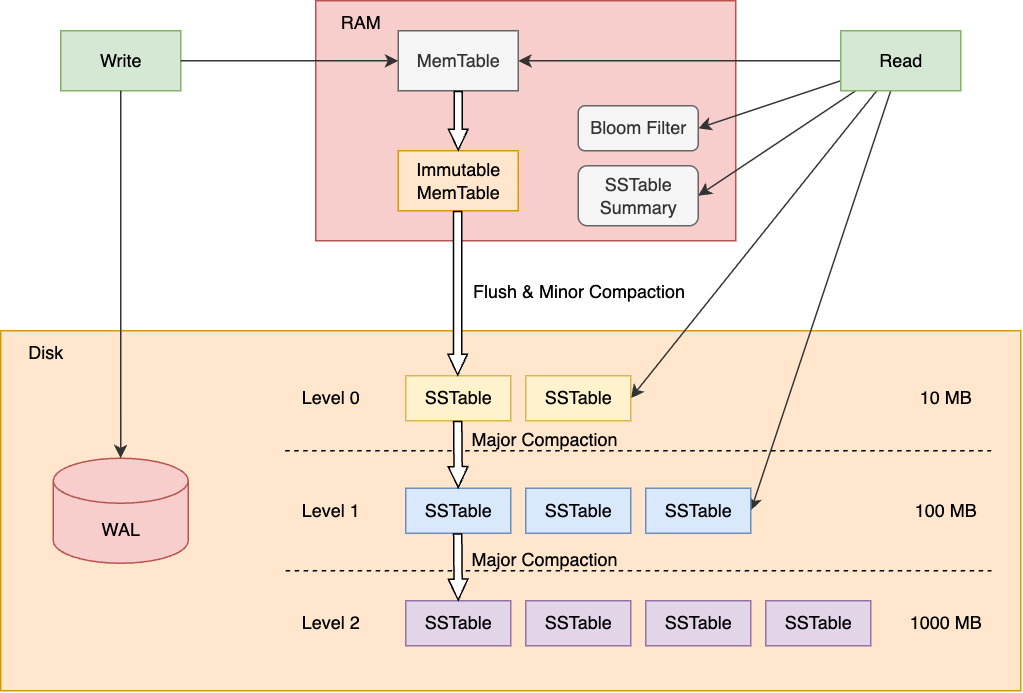
- 用户的插入、更新或删除操作首先记录在预写日志(WAL,Write-Ahead Log)中,以确保数据持久性。
- 然后,这些操作追加到内存中的 MemTable(Level 0)。
- 当 MemTable 达到阈值时,它会被冻结(Immutable MemTable),并flush到磁盘,形成一个新的 SSTable 文件,置于 Level 0 或 Level 1。
- 后续写入继续到新的 MemTable 中。
- 这个过程避免了随机写,转而使用顺序追加,提升了写入吞吐量。
2. 读取过程
- 读取时,从内存中的 MemTable 开始查询。
- 如果未找到,则逐层向下查询磁盘上的 SSTables(从 Level 0 到更高层)。
- 由于每一层文件有序,可以使用二分查找或布隆过滤器(Bloom Filter)加速。
- 如果有多个版本的数据(如更新导致的),返回最新的版本。
- 读取可能涉及多层扫描,导致读放大(Read Amplification),这是 LSM-Tree 的一个权衡。
3. 合并过程(Compaction)
- 当某层文件数量或大小超过阈值时,触发 Compaction:将该层的多个 SSTables 合并成更少的有序文件,并可能向下层移动。
- 合并时,会删除重复键或无效数据(如墓碑标记的删除)。
- 常见策略包括:
- Leveled Compaction:LevelDB/RocksDB 默认使用,按层级合并,控制每层大小呈指数增长(例如,每层大小是上一层的 10 倍)。
- Size-Tiered Compaction:Cassandra 使用,按大小分组合并。
- Compaction 消耗 CPU 和 IO,但确保了数据的有序性和空间效率。
LSM-Tree 的优缺点
优点
- 高写入性能:通过内存缓冲和顺序写,适合高吞吐写场景,如日志系统或时序数据库。
- 低成本存储:适用于 SSD 或 HDD,利用磁盘顺序访问。
- 易于实现压缩和备份:数据文件不可变,便于快照和复制。
- 支持范围查询:由于有序结构,扫描效率高。
缺点
- 读放大:查询可能需扫描多层,导致延迟。
- 写放大:Compaction 会多次重写数据,消耗 IO。
- 空间放大:临时保留旧版本数据,可能占用更多空间。
- Compaction 开销:在高负载下,可能导致性能抖动。
为了缓解这些问题,许多实现引入了布隆过滤器、缓存或优化 Compaction 策略。
来源:程序园用户自行投稿发布,如果侵权,请联系站长删除
免责声明:如果侵犯了您的权益,请联系站长,我们会及时删除侵权内容,谢谢合作! |
|
|
|
|
|
|
相关推荐
|
|
|



 提升卡
提升卡 置顶卡
置顶卡 沉默卡
沉默卡 喧嚣卡
喧嚣卡 变色卡
变色卡 千斤顶
千斤顶 照妖镜
照妖镜



