译者注:其中 “宠物与牛” 对应 DevOps 中的 “Pets vs Cattle”。我没有想出更好的简化翻译方式,可以参考此文章进行理解。
计算团队(Compute Team)负责管理与运行工作负载相关的基础设施,并花费了大量时间来定义和完善我们的升级流程来改善现状。升级会先在专用的集群集上测试,然后按照优先级从低到高的顺序发布到生产环境。这次升级是我们团队本季度的重点任务之一,而作为公司最重要的集群之一:运行着我们技术栈中“遗留部分”(社区亲切地称为 Old Reddit)的集群,已准备好升级到下一个版本。负责此项工作的工程师在 UTC 时间 19:00 刚过就启动了升级,起初的 2 分钟一切正常。然后混乱降临。
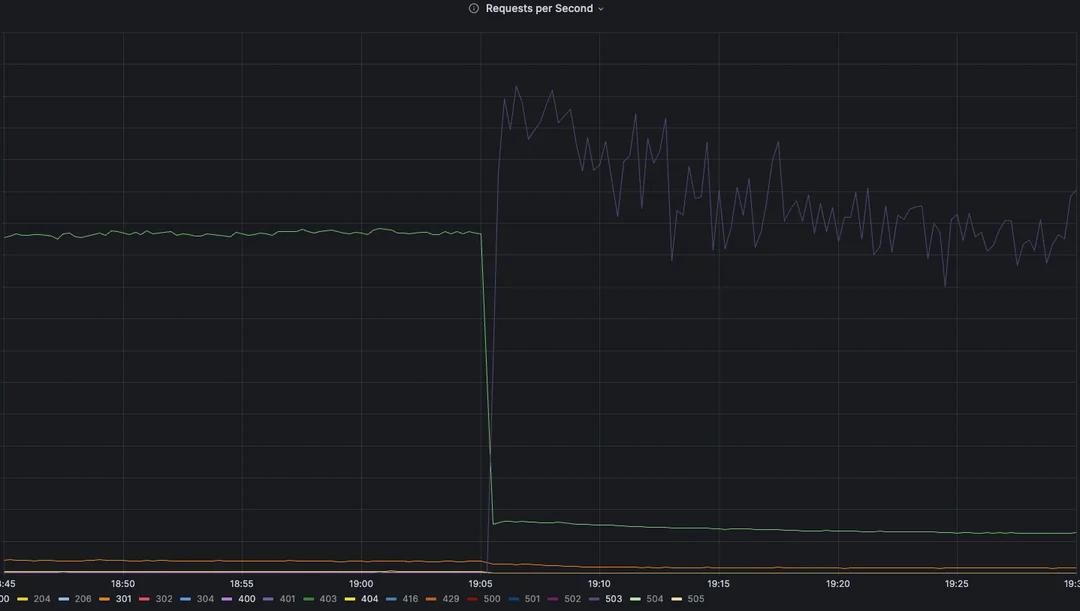
Reddit 边缘流量,按 RPS 统计
网站瞬间陷入瘫痪。我们立即创建了事故工单,并召集所有人手排查问题。在 T+3 分钟内已全员就位。我们发现的第一件事是:受影响的集群完全丢失了所有指标(上图显示的是我们 CDN 边缘的统计数据,这些数据特意与主数据分开展示)。我们完全摸不着头脑。唯一明显的线索是 DNS 解析失败了。我们无法解析 Consul(用于跨环境动态 DNS 的服务)中的记录,也无法解析集群内的 DNS 条目。但奇怪的是,公共 DNS 记录的解析却一切正常。我们顺着这条线索查了一会却一无所获。这是我们在之前的任何升级或测试中从未见过的新问题。
面对部署失败,立即回滚是首选方案,我们第一时间也考虑过这点。但亲爱的 Redditor 们,k8s 并没有官方支持的降级流程。因为在升级过程中,k8s 会自动执行许多架构、数据迁移操作,所以没有回头路。因此,降级意味着必须从备份中恢复并重新加载状态!
我们向来谨慎,备份当然是升级流程中的标准动作。然而这个备份和恢复程序是几年前写的。尽管它在我们的小型测试集群中经过了反复、全面的测试,但它并没有完全跟上生产环境的变化,而且我们从未在生产集群上使用过它,更别说在这个集群上了。这意味着我们不确定执行恢复操作需要多久,但初步估计至少是数小时的停机时间。因此我们决定继续调查并尝试找到解决方案。
故障的表现形式



 提升卡
提升卡 置顶卡
置顶卡 沉默卡
沉默卡 喧嚣卡
喧嚣卡 变色卡
变色卡 千斤顶
千斤顶 照妖镜
照妖镜



