LLM的狂风已经吹了几年, 所有人都耳濡目染的会飚上几句行话/名词。切好你自己有台4070的机器,恰好你有时间倒腾, 那就让我们回顾一遍名词,验证狂风吹过的技术车辙。
恰好最近有台4070(12g显存)机器,于是尝试使用ollama部署大模型。
RTX 4070 擅长训练中小型模型;凭借其 184 个 Tensor Core,它可以高效处理矩阵乘法等运算,这对于深度学习任务至关重要。
RTX 4070 适用于实时推理应用,提供快速的推理速度,使其成为聊天机器人和推荐系统等交互式 AI 应用的理想选择。
本次会用到3个名词
基于nvidia managemant library(NVML)之上的命令行工具,用于管理和监控nvidia GPU设备, 随显示驱动一起分发。
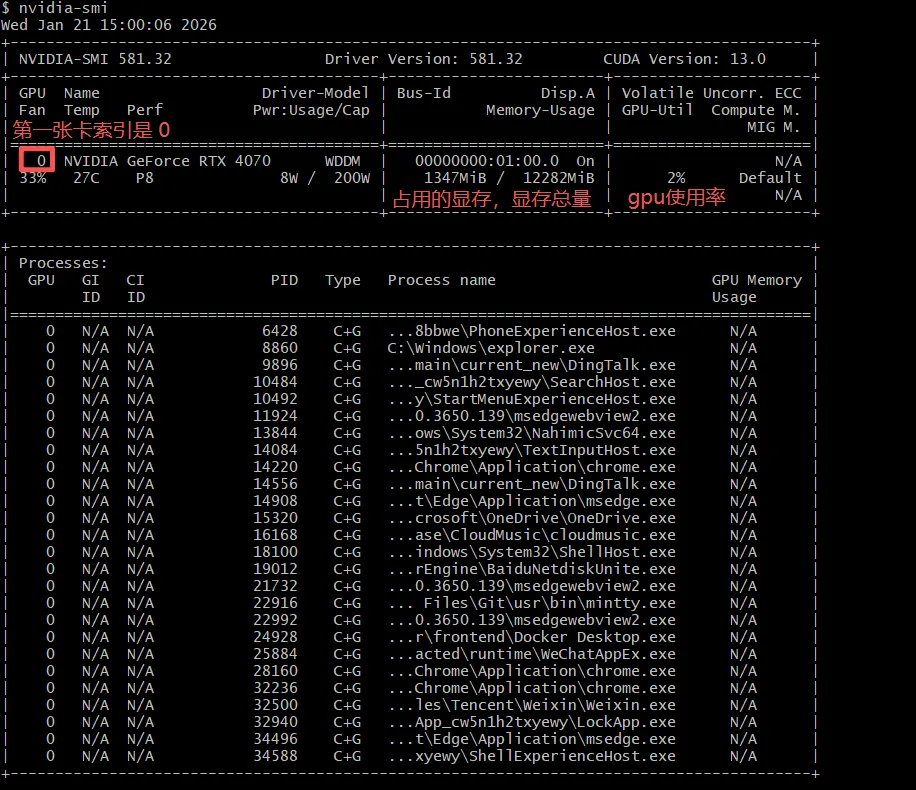
以下是未部署大模型时候的资源消耗快照, nvidia-smi -l 可持续监控gpu使用。
- 第一行显示了nvidia-smi版本/驱动版本/CUDA版本
- 0 表示nvidia 4070是第一张显卡, 索引的概念,下面的进程关联了这块显卡0
- Fan Temp Perf Pwr 分别显示GPU的当前风扇转速、温度、性能状态和功耗
- Memory-Usage 当前显存使用量和总显存(12g)
- GPU_Util 显示当前GPU计算能力的百分比
- Compute M 表示当前计算模型: compute
ollama是mata开源的,定位是模型管理器和推理框架,帮助用户傻瓜式在本地、k8s集群、虚拟机上部署开源大模型。
ollama -h提供了可用命令,也显示了可用的能力:创建模型、管控部署模型。
ollama是服务端-客户端架构,有后台服务进程olllama.exe,提供了GUI终端和命令行工具可交互,另外提供sdk和restful api,可供各种程序或者语言操作ollama。- ollama listNAME ID SIZE MODIFIEDqwen3-embedding:latest 64b933495768 4.7 GB 15 hours agoqwen3:8b 500a1f067a9f 5.2 GB 23 hours ago## size 是预估的显存大小
- qwen3:8b vs qwen3-embedding
8b表示80亿参数(8 Billion parameters)
除了chat模型, 还有嵌入模型embedding, 嵌入模型是将文本/image数据向量化的最新手段。
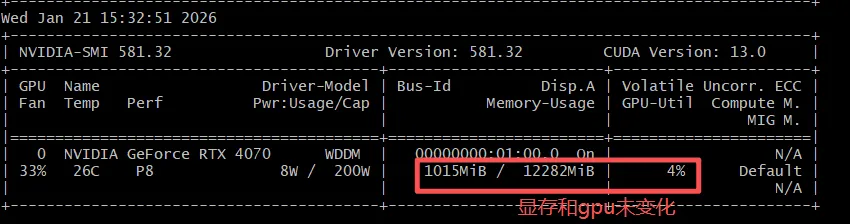
下载完ollama, 选择qwen3:8b大模型,开始下载模型。
1. ollama run qwen3:8b
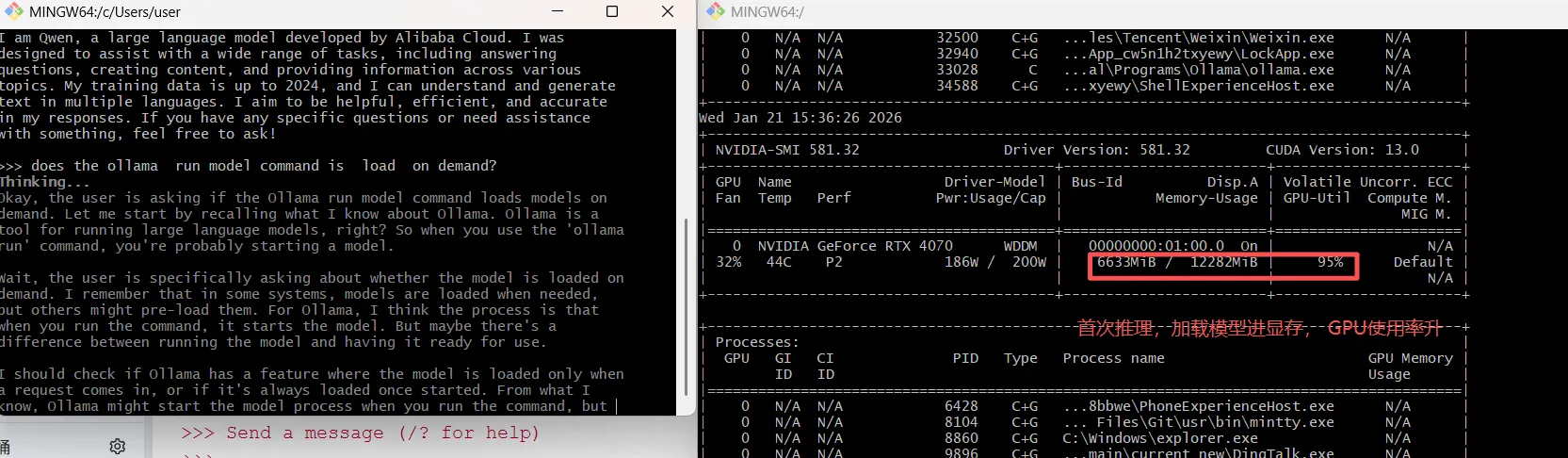
- $ ollama run qwen3:8b>>> Send a message (/? for help)
首次推理请求, 显存使用稳定在6g, gpu使用率上升,推理结束,显存使用率不会降, gpu使用率回落, 说明ollama是按需加载大模型。
2. ollama run [model] vs ollama serve
ollama serve意味着启动ollama作为web服务(不意味着当前启动了大模型),默认在http://127.0.0.1:11434/监听,外部可使用restful api或者client sdk操作ollama、操作模型、与模型对话。
[code]curl http://localhost:11434/api/chat -d '{ "model": "qwen3:8b", "messages": [{ "role": "user", "content": "Hello there!" }], "stream": false}'{"model":"qwen3:8b","created_at":"2026-01-21T07:57:52.9621534Z","message":{"role":"assistant","content":"Hello! How can I assist you today?
来源:程序园用户自行投稿发布,如果侵权,请联系站长删除
免责声明:如果侵犯了您的权益,请联系站长,我们会及时删除侵权内容,谢谢合作! |


 提升卡
提升卡 置顶卡
置顶卡 沉默卡
沉默卡 喧嚣卡
喧嚣卡 变色卡
变色卡 千斤顶
千斤顶 照妖镜
照妖镜



