参考
https://github.com/zhaochenyang20/Awesome-ML-SYS-Tutorial/blob/main/sglang/code-walk-through/readme-CN.md
https://github.com/sgl-project/sglang/tree/v0.5.5.post3
整体框架图
1 启动 Server(launch Sever)
SGLang 提供 SRT(SGLang Runtime)Server 用于服务 HTTP 请求以及一个不依赖 HTTP 协议的离线推理引擎。核心函数 launch_server 和 launch_engine 均定义在 server.py 中。其中,launch_engine 函数负责初始化核心 SRT Server 的组件。
设置 logging、Server 参数、CUDA/NCCL 环境变量以及进程间通信端口,配置 model 和 tokenizer。
如果 dp_size > 1,运行 run_data_parallel_controller_process 以启动多个 data parallel replicas;否则,在每个 tp_rank 上,以子进程的方式初始化一个 Scheduler,处理来自 TokenizerManager 的请求,并且管理 KV Cache。
在 Engine 主进程中运行 TokenizerManager,并以子进程形式运行 DetokenizerManager:前者负责 tokenize requests 并发送给 Scheduler,后者将 Scheduler 返回的 token ids 转换为文本,发送回 Server 前端。需要注意的是,在多节点推理中(例如,在两个节点上使用 共计 16 张 H100 部署 Llama 3.1 405B),TokenizerManager 和 DetokenizerManager 仅在第一个节点运行。
如果指定了 chat template,则将其启动,随后等待 Scheduler 进程发出全部进程准备就绪的信号,并且 Scheduler 的配置信息。
2 转发请求 (Forward Requests From Server)
Server 使用 FastAPI 应用定义 API endpoint,通过 v1_chat_completions 将 /v1/chat/completions 请求转发至 TokenizerManager。
从 raw_request 中解析 JSON 数据为 ChatCompletionRequest,将其转换为 GenerateReqInput,并通过 v1_chat_generate_request 配置 sampling_params。
调用 TokenizerManager 的 generate_request 方法并等待返回。得到返回后,根据 stream 参数处理流式(streaming)或非流式(non-streaming)响应。
对于流式响应,使用 generate_stream_resp 逐步处理 generate_request 的输出;对于非流式响应,等待异步返回的处理结果并通过 v1_chat_generate_response 转换为 ChatCompletionResponse。
3 TokenizerManager 生成请求(Generate Request In TokenizerManager)
TokenizerManager 由Server 主进程中的 launch_server 初始化,用于对请求进行 tokenization。
Initialization
设置 ZeroMQ 进行进程间通信,包括 TokenizerManager 与 DetokenizerManager 和 Scheduler 交互的 socket。
配置 server_args,启用 metrics,并初始化 model_config、tokenizer 以及多模态图像处理器的 placeholders。
generate_request
如果 TokenizerManager 的事件循环尚未初始化,则在此创建。
如果模型权重正在通过 update_weights_from_disk 或 update_weights_from_distributed 更新参数,则暂停处理。
验证请求类型是否与模型的 is_generation 设置匹配。
使用 normalize_batch_and_arguments 对请求进行归一化/标准化,以管理批处理、并行采样和默认参数。
对单个请求,通过 _tokenize_one_request 进行 tokenization,将请求发送至 Scheduler,并通过 _wait_one_response 等待响应。
对批处理请求,通过 _handle_batch_request 方法进行处理:tokenize 输入、管理并行采样、与 Scheduler 交互,并在流式和非流式模式下生成响应。
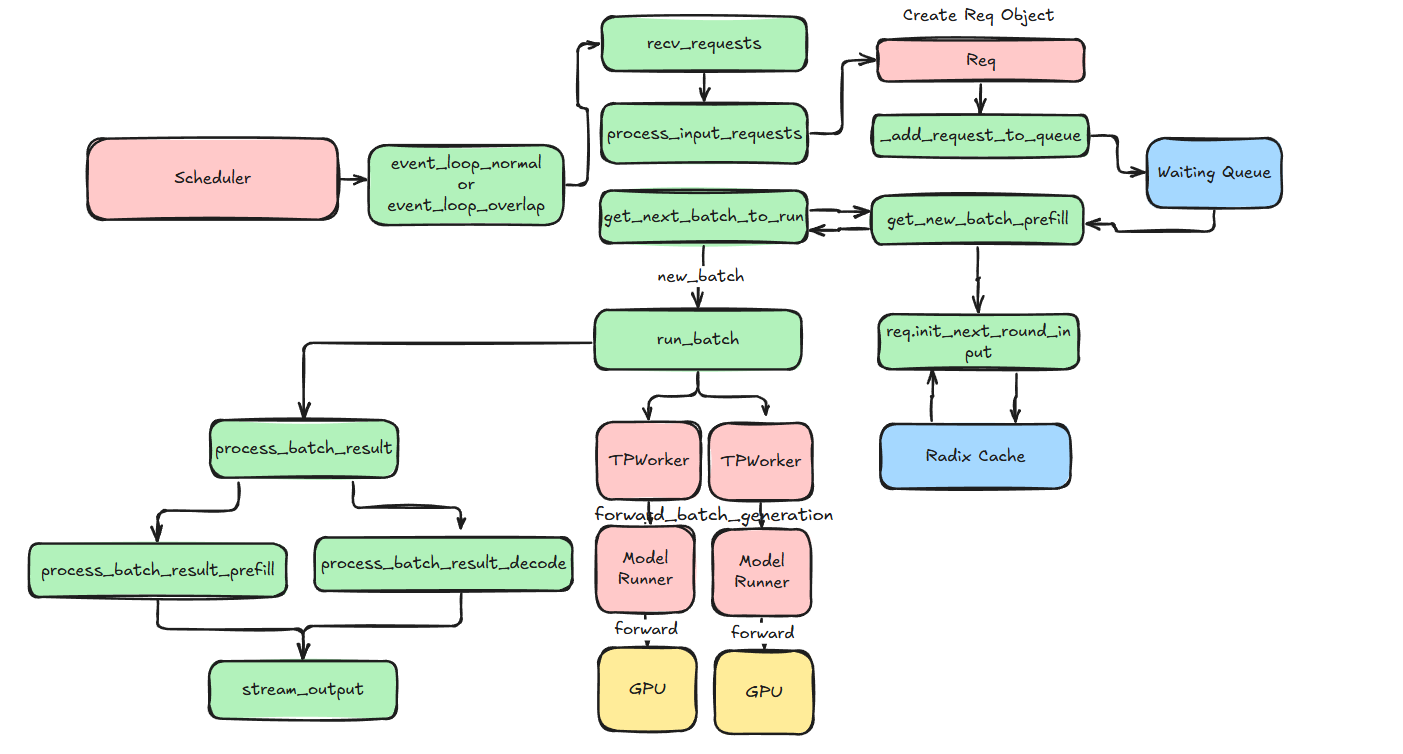
4 Scheduler 接收请求以及处理批次 (Scheduler Receive Requests and Process Batches)
这张图给出了 Scheduler 的概览:
Scheduler 作为 Server 的子进程运行,通过 run_scheduler_process 初始化,并通过 event_loop_normal 或 event_loop_overlap 执行无限的事件循环。
Initialization
配置 ZeroMQ 用于与 TokenizerManager 的通信。
设置 server_args、port_args、model_config、sessions,并根据重叠调度(overlap scheduling)的方式初始化 TpModelWorker 或 TpModelWorkerClient。
初始化分词器和处理器,使用 ChunkCache 或 RadixCache 进行缓存管理,配置 SchedulePolicy。
配置 chunk prefill 参数,并为 constraint decoding 请求初始化 GrammarBackend。
Event Loop
Scheduler 不断执行由 process_input_requests、get_next_batch_to_run、run_batch 和 process_batch_result 构成的无限事件循环。
process_input_requests
遍历接收到的请求,识别其类型并将其分派给相应的处理函数。
get_next_batch_to_run
- 1、尽可能将 last_batch 与 running_batch 合并,并通过 get_new_batch_prefill 优先处理 prefill batch。
- 2、如果没有 prefill batch,则更新用于 decode batch 的 running_batch,包括过滤请求、管理显存并调整解码参数。
run_batch
- 1、对于生成模型,使用 TpModelWorker 的 forward_batch_generation 生成新的 token,或在空闲状态中使用 forward_batch_idle,并将结果返回至 event_loop_normal。
- 2、对于嵌入或奖励模型,执行 forward_batch_embedding,并返回 embeddings。
process_batch_result
在执行完 run_batch 后,Scheduler 在 event_loop_normal 中处理批量结果:
- 1、Decode 模式:处理输出,更新请求状态,处理标记和概率数据,管理内存,并记录统计信息。
- 2、Extend 模式:处理预填充结果,处理输入标记,并为进一步解码或嵌入做准备。
- 3、已完成的请求通过 cache_finished_req 缓存,并流式传输到 DetokenizerManager。未完成的请求会被更新,并循环回 get_next_batch_to_run 进行进一步处理,直至完成。
需要注意的是,LLM 推理按照计算特性不同,通常分为 Prefill 和 Decode 阶段。对于 Prefill 和 Decode 的概念,可以参考 HuggingFace 的这篇文章。而在 SGLang 中,大多数情况下使用的是 extend mode,而非 prefill mode。Prefill 模式为新请求初始化 KV-Cache,通常使用 Paged KV-Cache。而 Extend 模式则利用 Ragged Tensors 增量更新现有的 KV-Cache,效率更高,这使其非常适合 SGLang 面向的长序列或多轮对话请求。
5 TpModelWorker 管理 forward pass 和 token sampling (TpModelWorker Manage Forward and Token Sampling)
TpModelWorker 负责管理 ModelRunner 的 forward pass 和 token sampling 操作,从而完成由 Scheduler 调度的批次请求。
Initialization
- 1 初始化 tokenizer、模型配置和 ModelRunner。
- 2 配置设备信息和 memory pool。
forward_batch_generation
- 1 创建 ForwardBatch,通过 ModelRunner 的 forward 计算 logits,并使用 ModelRunner 的 sample 采样得到下一个 token。
- 2 将 logits_output 和 next_token_ids 返回给 Scheduler,用于 Scheduler 的 process_batch_result。
forward_batch_embedding
- 1 创建一个 ForwardBatch,通过 ModelRunner 的 forward 获取 logits_output 和 embeddings。
- 2 embedding 请求不需要采样,因此跳过 ModelRunner 的 sample 过程,直接将 embeddings 返回给 Scheduler。
6 ModelRunner 管理模型执行 (ModelRunner Manages Model Execution)
ModelRunner 初始化 AttentionBackend 并管理加载的模型,以执行 generation 和 embedding 任务的 forward pass。
Initialization
初始化分布式环境,加载模型,启动 tensor parallel,并设置 memory pool 和 AttentionBackend。
forward
forward 函数根据 forward_mode 决定适当的前向模式来处理批次:
- 1 forward_decode:初始化 forward metadata 并调用模型的 forward,传入 input IDs 和 position。
- 2 forward_extend:初始化 forward metadata 并调用模型的 forward 进行 generation 或 embedding 任务。
- 3 forward_idle:当前向模式为空闲时,管理空闲的前向传递。
7 Model 加载权重并执行前向传递 (Model Load Weights and Perform Forward)
ModelRunner 的 self.model 是 Model class 的一个实例。所有 支持的模型 都可以在 python/sglang/srt/models 中找到。我们以 Qwen2ForCausalLM 为例。
Qwen2ForCausalLM 的结构如下:
- model:用于前向传递的权重。
- embed_tokens:将 input_ids 转换为 embeddings。
- lm_head:将 hidden states 映射回 vocabulary space。
- logits_processor:处理 logits 以便进一步 sampling 或者 normalization。
- pooler:用于提取 embeddings 或计算 rewards 的 pooling 机制。
forward
Qwen2ForCausalLM 中的 forward 函数处理 input IDs,生成用于预测下一个 token 的 logits,或生成用于奖励/嵌入请求的 embeddings:
使用 embed_tokens 将 input_ids 转换为 embeddings。将 embeddings 依次通过多个 Qwen2DecoderLayer 层完成 forward pass。
如果 get_embedding 为 True,则通过 pooler 返回 embeddings;否则,使用 logits_processor 计算 logits 并返回。
SGLang 对模型推理的加速主要来自于 forward_batch 与 AttentionBackend 之间的交互。
8 AttentionBackend 加速模型前向传递 (AttentionBackend Accelerate Model Forward)
SGLang 支持多个 Attention Backends,这些 backends 加速模型的 forward pass 和 key-value cache reuse。我们以 FlashInferBackend 为例。
Initialization
- 1 配置 sliding window 和 cross-attention 场景的 wrappers。
- 2 分配必要的 buffers 和 key-value 索引。
- 3 为高效的注意力计算准备 forward metadata。
- 4 集成 CUDA Graphs 支持以优化执行路径。
init_forward_metadata
- 1 decode mode:使用 indices_updater_decode 更新 decode 的索引,并设置 forward_metadata 以使用 decode_wrappers。
- 2 extend mode:根据 token 和 wrappers 的数量确定是否需要 ragged forward,随后使用 indices_updater_prefill 更新索引。
- 3 分配 metadata:设置 forward_metadata,为 ragged forward 和 prefix extension 设置 flags。
forward_extend 和 forward_decode
- 1 对 forward_extend,根据 ragged 或者 paged attention,选择合适的 wrapper。对 forward_decode,选择 decode wrapper。
- 2 计算 attention,管理 key-value cache,并返回 reshaped 后的输出。
9 DetokenizerManager 进行解码并发送回 TokenizerManager (DetokenizerManager Detokenize and Send to TokenizerManager)
DetokenizerManager 在 launch_server 中被初始化为 Server 的子进程,用于将 Scheduler 返回的 token ids 转换为文本,并发送回 TokenizerManager。
Initialization
设置 ZMQ communication socket 和 tokenizer。使用 LimitedCapacityDict 管理 decode status。
event_loop 和 trim_eos
- 1 接收来自 Scheduler 的处理请求,直接转发 BatchEmbeddingOut 或处理 BatchTokenIDOut 进行 detokenization。
- 2 将 token ID 拆分为 read_ids 和 surr_ids。使用 batch_decode 将 token ID 转换为文本。更新 DecodeStatus,包括新的 offsets 和 detokenized text。
- 3 在序列的停止处整理输出,将 detokenized text 与 metadata 合并成 BatchStrOut,并发送回 TokenizerManager。
10 FastAPI 整理并输出 (FastAPI Wraps the Output)
- 1 DetokenizerManager 通过 ZeroMQ 将 BatchStrOut 发送到 TokenizerManager。
- 2 TokenizerManager 更新请求状态并为 FastAPI 准备 detokenized text。
- 3 最后,在 FastAPI 中,对于流式传输,使用异步生成器和 StreamingResponse 将响应发送给用户。
- 4 对于非流式传输,收集并使用 ORJSONResponse 发送完整响应,并返回给用户。
来源:程序园用户自行投稿发布,如果侵权,请联系站长删除
免责声明:如果侵犯了您的权益,请联系站长,我们会及时删除侵权内容,谢谢合作! |
|
|
|
|
|
|
相关推荐
|
|
|



 提升卡
提升卡 置顶卡
置顶卡 沉默卡
沉默卡 喧嚣卡
喧嚣卡 变色卡
变色卡 千斤顶
千斤顶 照妖镜
照妖镜



