今天我特地花时间全流程熟悉了一下魔搭社区,很多人都说它是国内版的 Hugging Face,想跟大家分享一下我的一些总体感受。首先,的确像大家说的那样,它提供了很多免费的额度。比如,CPU 机器是完全免费的,而且没有时长限制;GPU 机器的免费时长是 36 小时,我注册得比较早,看到现在新用户是 100 小时。其实当初我注册的时候挺犹豫的,因为完全没接触过这个领域,怕搞不懂。但现在看来,总体体验还是挺不错的。
不过,毕竟它是一个偏向开发者的社区类型,遇到报错什么的,有时候真的很难快速找到解决办法。今天我在操作过程中就遇到了好几个问题,几乎都是自己摸索着解决的,找不到人帮忙。而且,社区里面的相关文章也比较少,几乎没法直接找到很有用的资料。唯一能依赖的就是提 issue,虽然感觉这不是最快的解决方案。
我之前按照 GitHub 上的教程,用代码微调了下 Qwen-7B,虽然效果是有出来的,但中间的流程我完全搞不懂,尤其是那些一堆密密麻麻的参数,真的是看得头大。后来发现魔搭提供了一个叫哥Swift的轻量级框架,它有可视化界面,这才让我有了兴趣去试一试。整体来说,用起来确实挺方便的,我根本不用去管那些复杂的参数设置,就算偶尔想调一下,也只是点点页面上的选项就行了。毕竟我是个小白,能有个简单直观的工具帮我入门,感觉挺适合像我这种初学者的。
好的,废话不多说,今天我就带大家一起看看,怎么利用魔搭社区零花销快速训练和微调一个模型,然后发布到社区里,让其他人也能用到它。
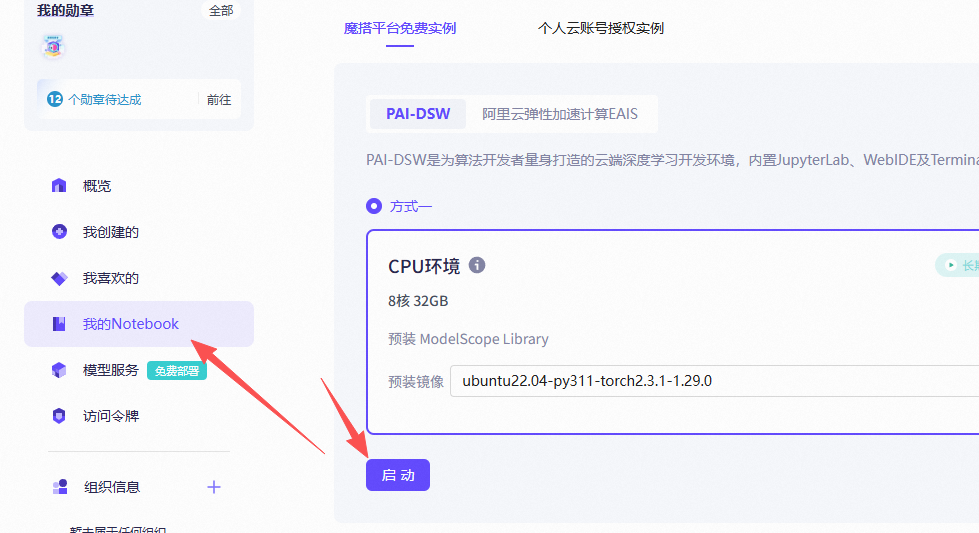
创建实例
魔搭社区的网址是:https://www.modelscope.cn。
对于还不太熟悉的小伙伴们,建议可以先去社区里逛一逛,了解一下它都提供了哪些功能。其实我们最常用的两个功能就是模型库和数据集,当然啦,如果能用到免费的机器那就更好了,要不然还得自己去租台机器来用。
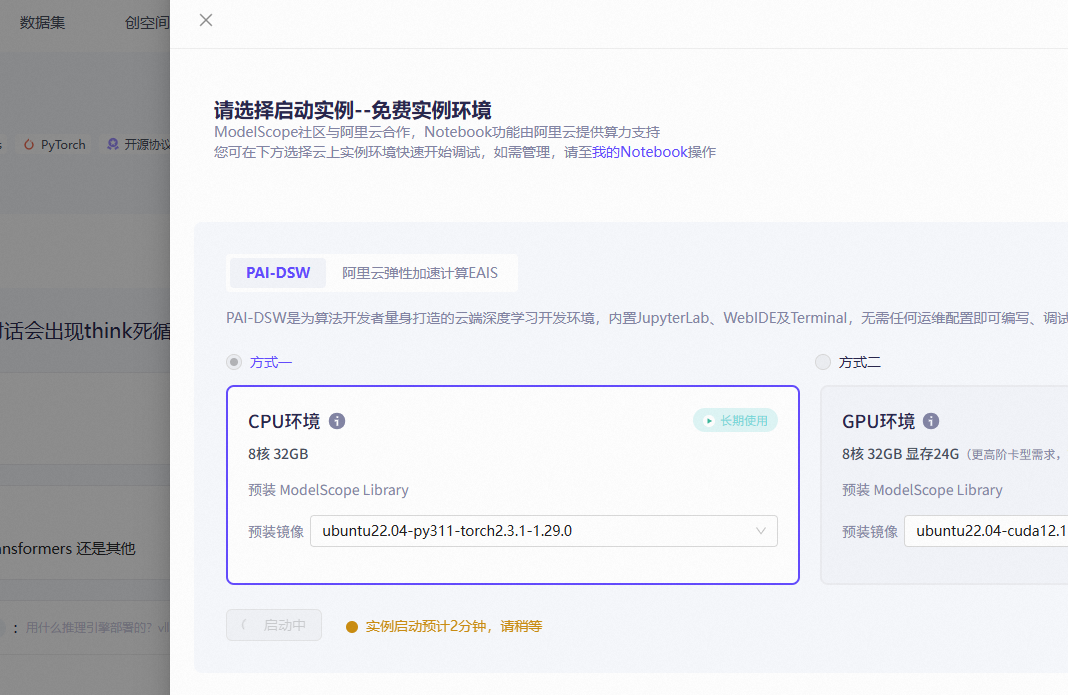
逛完之后,我在模型库里找到了一个下载量超高的模型——qwen-32b。为了不花钱、先熟悉一下操作,我决定先看看它能不能直接部署在机器上。然后,我选择了CPU环境来部署,因为GPU环境的使用时长是有限制的。你们可以参考下图:
CPU实例
试水Qwen3-32B
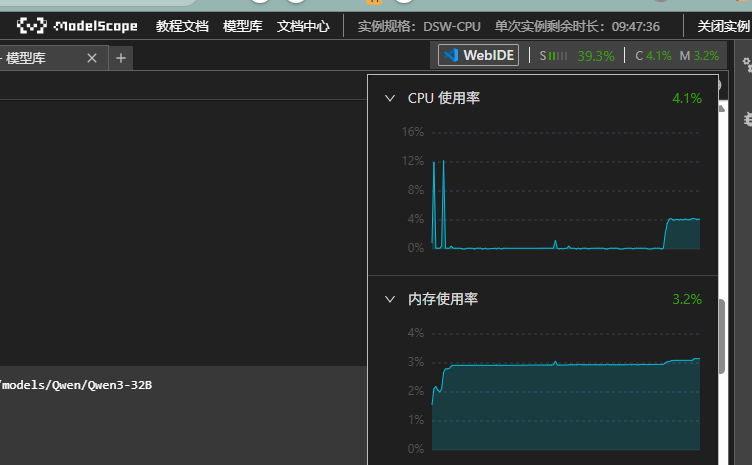
进去之后,你会看到一个跟常见的 VS Code 很像的编辑器,界面挺熟悉的。不同的是,它还会显示当前机器的一些配置信息,比如 CPU、GPU、存储空间等,方便你随时了解系统的资源状态。
里面啥也没有,只有一个我当时选的模型——Qwen3-32B的入门notebook。这个notebook挺基础的,内容都比较简单,但是也很友好,特别适合刚开始接触的朋友。
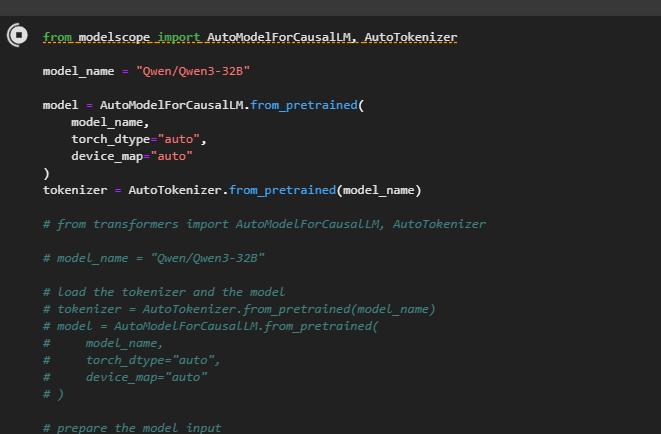
我找到了一个代码片段,先不管啥,直接跑了一下,结果一上来就报错了。原来是它试图从 Hugging Face 社区下载模型,但因为网络问题没法连上。我去他们的问答区查了一下,简单修改了几下,像图中这样:
他现在可以直接从国内的魔搭社区下载了。等了好一阵,结果没想到32B模型竟然占了几十个G的存储,直接就把一半硬盘空间给占满了。如果还要调试什么的,100G的存储基本就不够用了。
因为下载的时间实在是太长了,我就先放那儿不管了。结果过了大概一个小时,实例就直接被关掉了,真是尴尬。赶紧搜了一下,发现首页有个入口可以重新启动实例环境,赶紧点开启动了。
启动之后,页面上会出现一个“查看notebook”按钮,但不要急着点那个按钮哦。因为浏览器有时候可能会显示一个“no health upstream”的错误提示,我之前就碰到过。这个问题其实不用担心,只要稍微等一下就好。等了一会儿之后,页面就正常加载了,最后确认我们的模型确实已经成功下载了。
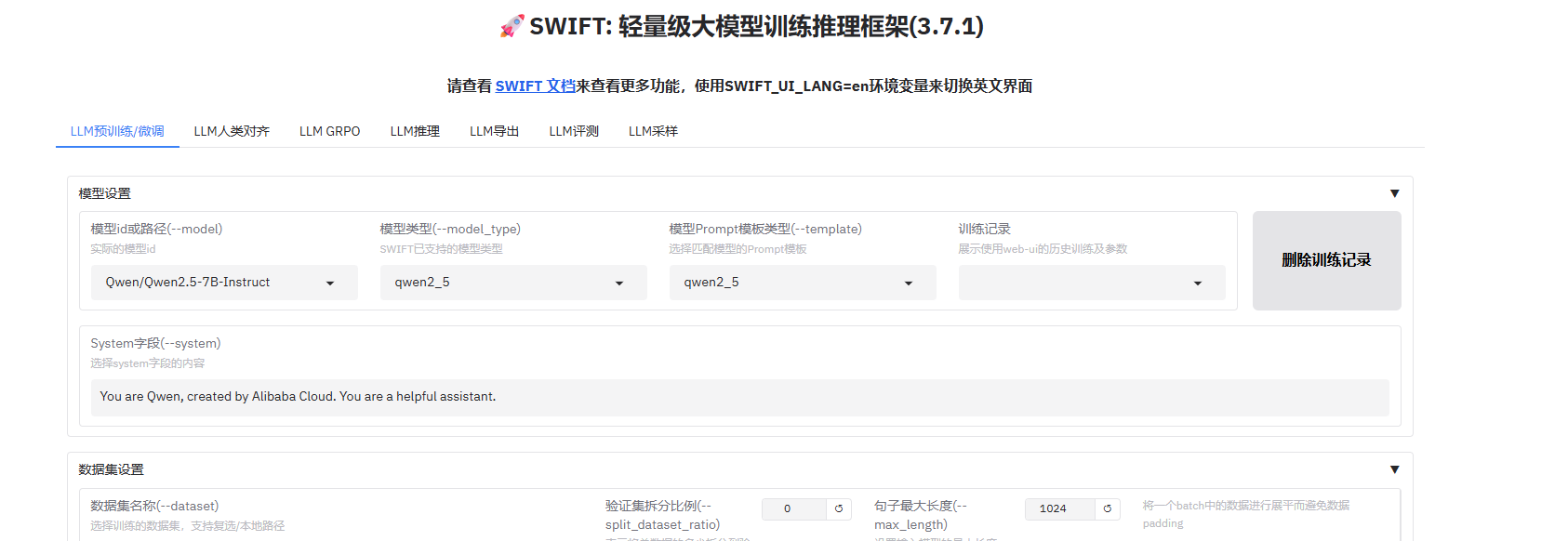
SWIFT可视化操作
因为我当时的目标很明确,就是简单地训练模型并发布它,毕竟这是我第一个要跑通的案例。所以,我就按照官方文档一步步操作。翻了一下文档后,发现有个叫SWIFT的框架,看起来很合适,而且界面超级友好,一看就能上手。
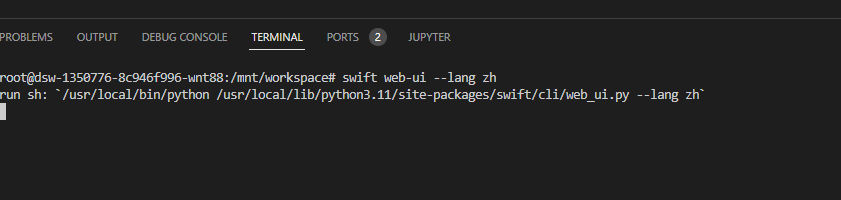
于是,我直接在终端控制台里输入了下面两条命令,快速启动。
pip install 'ms-swift'
swift web-ui --lang zh
对了,有一点很重要,启动CPU实例和GPU实例其实没有太大区别,机器里的内容是完全一样的。所以你不用担心它们之间不能互通的问题。如果某些操作只需要CPU就能搞定,那就启动CPU实例就好;但如果你需要进行一些更复杂的训练,想要用到GPU加速,那就再启动GPU实例。
简单来说,根据需求切换就行,完全不用担心其他的。
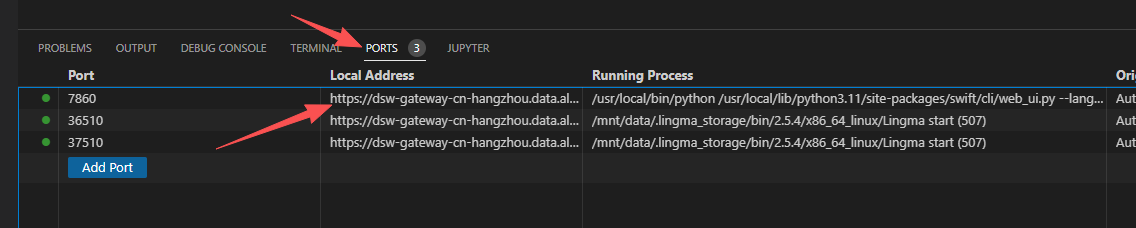
命令执行完毕之后,如果启动时没有提醒你去打开浏览器页面,没关系,你可以去‘port’标签下找一下 Swift 的端口,直接点击那个地址就能进入浏览器查看了。
你一打开就会看到一个简洁明了的首页界面,如图所示:
因为我知道32B模型训练起来可能会挺耗时间和计算资源的,所以我就直接选择了8B的相对小一些的模型,先试试效果如何。直接选择就行了,像图中这样操作就可以了:
页面一报错,我本来想看个具体信息,结果什么都没显示。于是我就直接切回notebook后台看了看。如图所示:
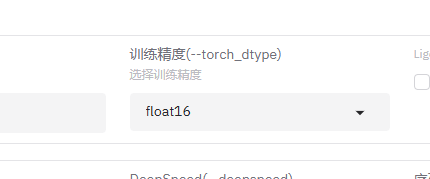
我也在页面上看到了这个参数。大概理解是,因为我没有GPU,所以CPU不能使用bf16这个功能吧。
我就改成了float16.结果还是报错:
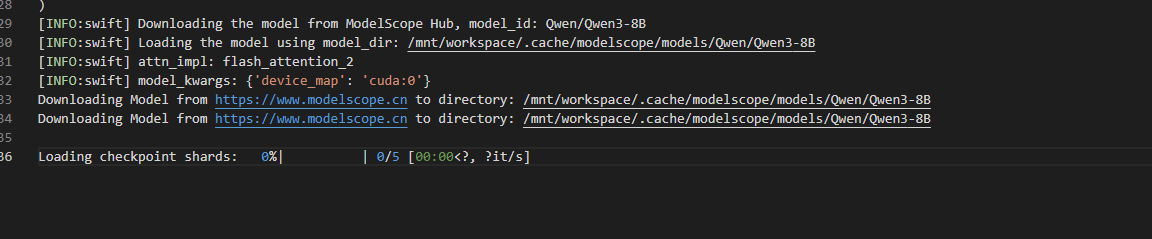
ImportError: FlashAttention2 has been toggled on, but it cannot be used due to the following error: the package flash_attn seems to be not installed. Please refer to the documentation of https://huggingface.co/docs/transformers/perf_infer_gpu_one#flashattention-2 to install Flash Attention 2.
GPU实例
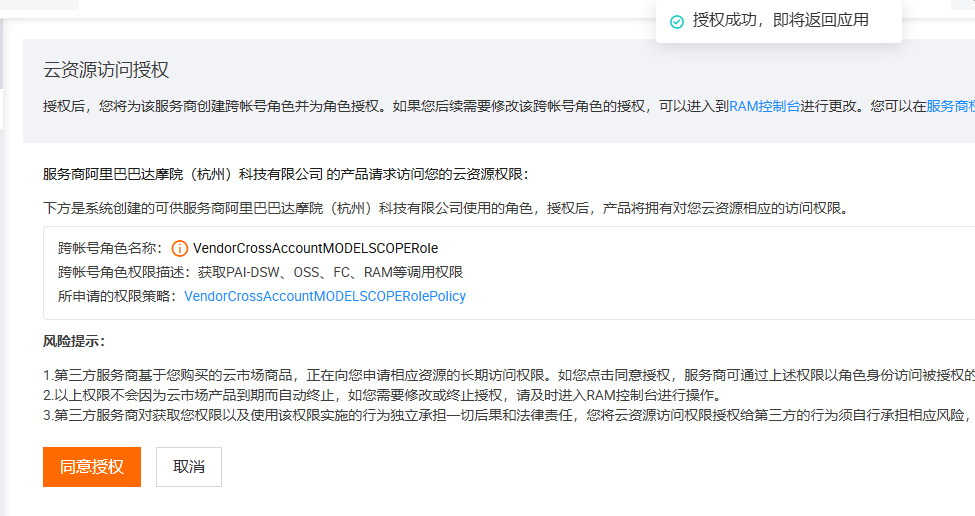
好嘛,既然都知道是怎么回事了,我干脆放弃用CPU,直接切换到GPU启动。反正也没啥大不了的。不过,启动之前还是得先授权一下,如图所示:
注意啊,其实我们不需要一步一步全做完。这里面显示了三步,但第三步其实是收费的步骤,我们并不需要去创建那个实例。说实话,那不是我们需要的东西,而且一小时大概要10块钱左右,所以不用去做。
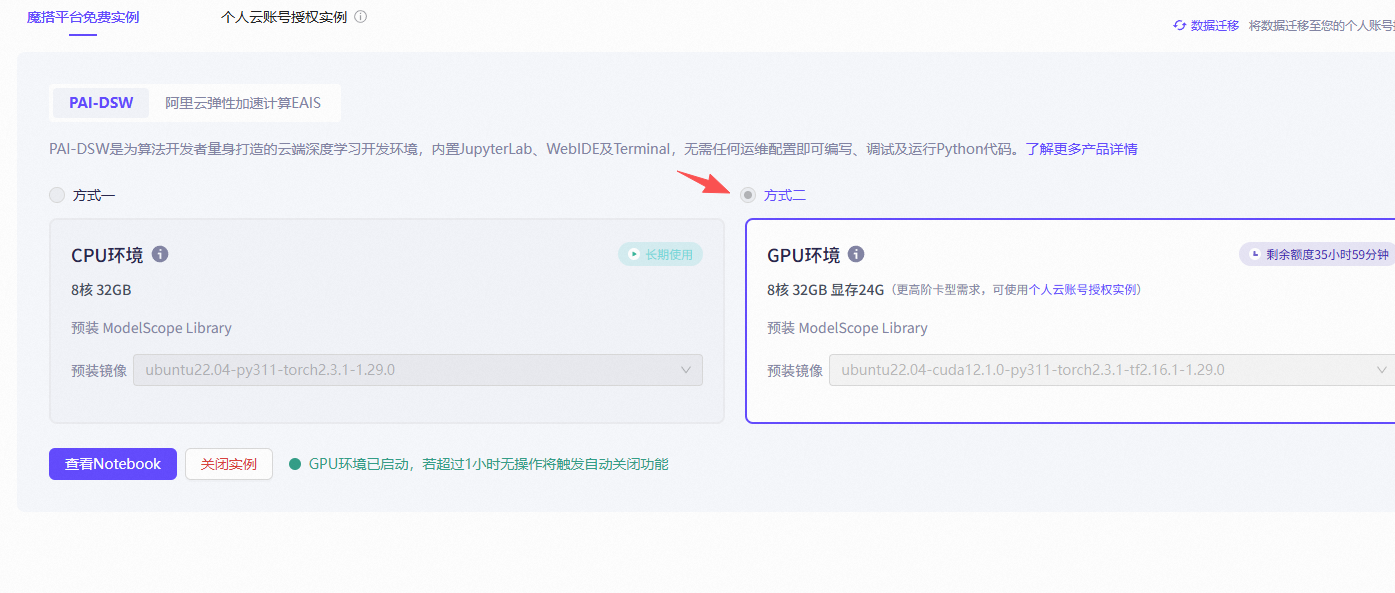
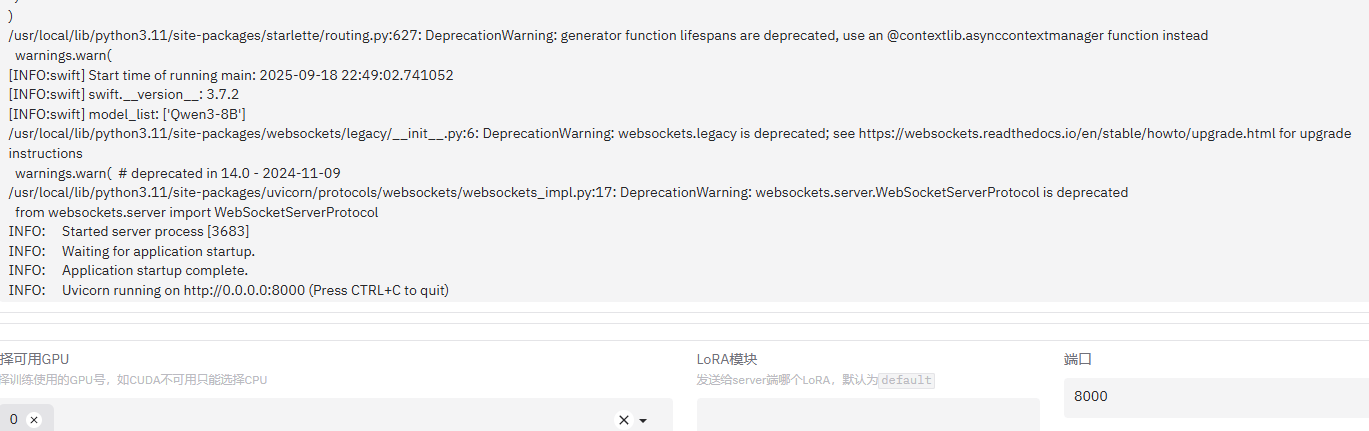
好的,那我们接着来说一下魔搭平台的免费实例。你可以直接选择一个GPU环境的实例,操作非常简单,选好后就可以直接启动了。这样你就可以开始使用了,十分方便。
模型训练
你看,虽然启动方式不太一样,但我们内部的应用信息都还是保留着的,命令一打就能直接启动,因为Swift已经在我们的CPU环境中安装好了。
启动之后,我直接就开始训练了。我用的是文档里提供的数据集(链接:https://modelscope.cn/datasets/swift/self-cognition)
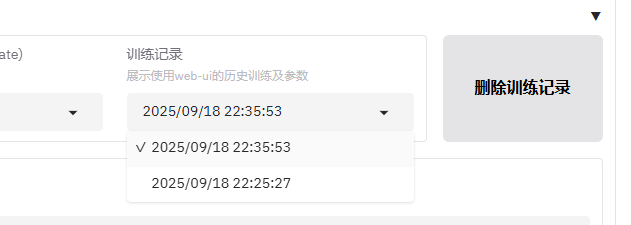
直接在数据集选项框里复制粘贴进去就行,选不到的话也不用担心,系统会自动帮你下载好。训练过程中,你也能随时在页面上查看相关的训练记录。我这里的过程非常顺利,没有遇到任何报错。
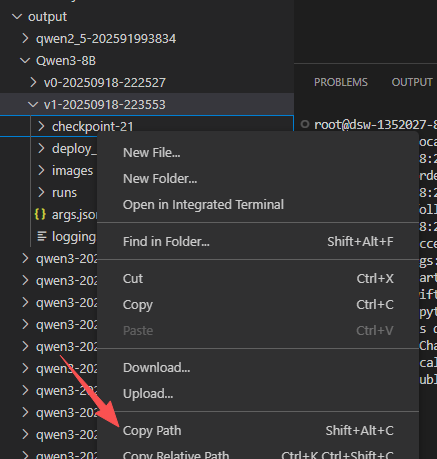
训练成功后,模型会自动生成在 output 目录下。我们接下来只需要复制一下 checkpoint 这个目录的路径,因为稍后我们会用到它。具体操作可以参考下图:
模型推理
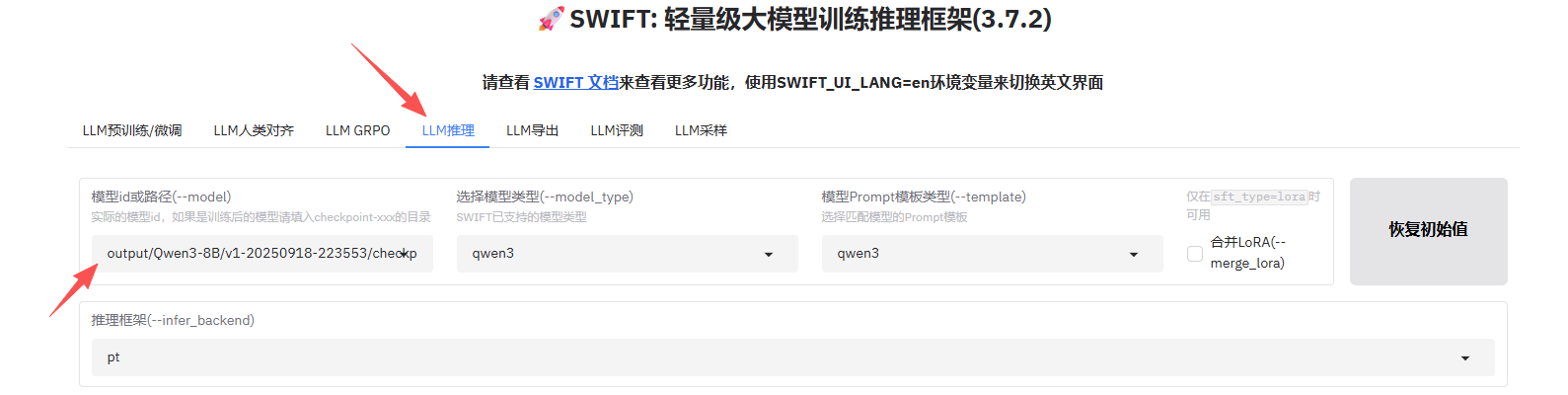
因为我们的训练已经完成了,所以接下来直接去LLM推理那一页,找到“model”参数输入框。在这里,我们不需要选什么现成的模型,而是直接把刚刚训练好的checkpoint粘贴进去就行了。具体操作可以参考下面的图示。
output/Qwen3-8B/v1-20250918-223553/checkpoint-21
部署模型
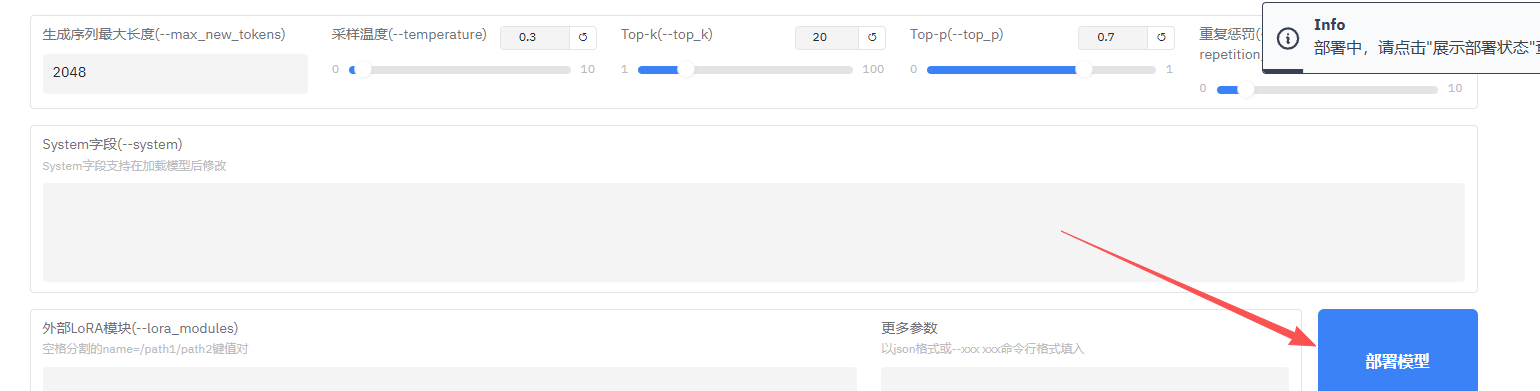
然后我们需要先部署才能对话。稍等片刻,如图所示:
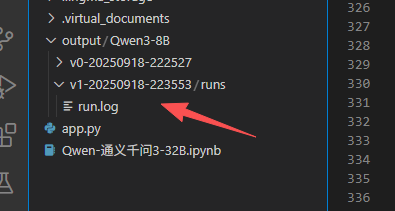
在这个时候,页面上也会显示部署的状态日志。如果你发现页面的 WebUI 没有显示任何运行日志,不用担心,我也遇到过这种情况。其实日志会在 output 中生成,像图中展示的那样。
双击后,就能看到实时日志了,不用刷新文件,他会自动刷新。
在正常情况下,部署完成后,这里会显示绑定8000端口成功。也就是说,我们就可以开始进行模型对话了
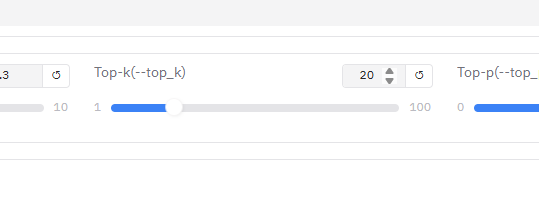
topk:invalid value
有时候呢,你在选完模型之后,界面会自动把某些参数给转换成float类型,就像我遇到的情况一样。表面上看界面一点问题都没有,也不会报错,感觉一切都挺正常的。可等你真正去部署的时候,才发现跑不起来,然后才报错,特别尴尬。下面就是我遇到的具体情况,给你参考一下。
自己去改一下就行,去掉小数点,再去点击部署就没毛病了。
对话
部署成功后,我们直接在最下方与微调后的模型进行对话。
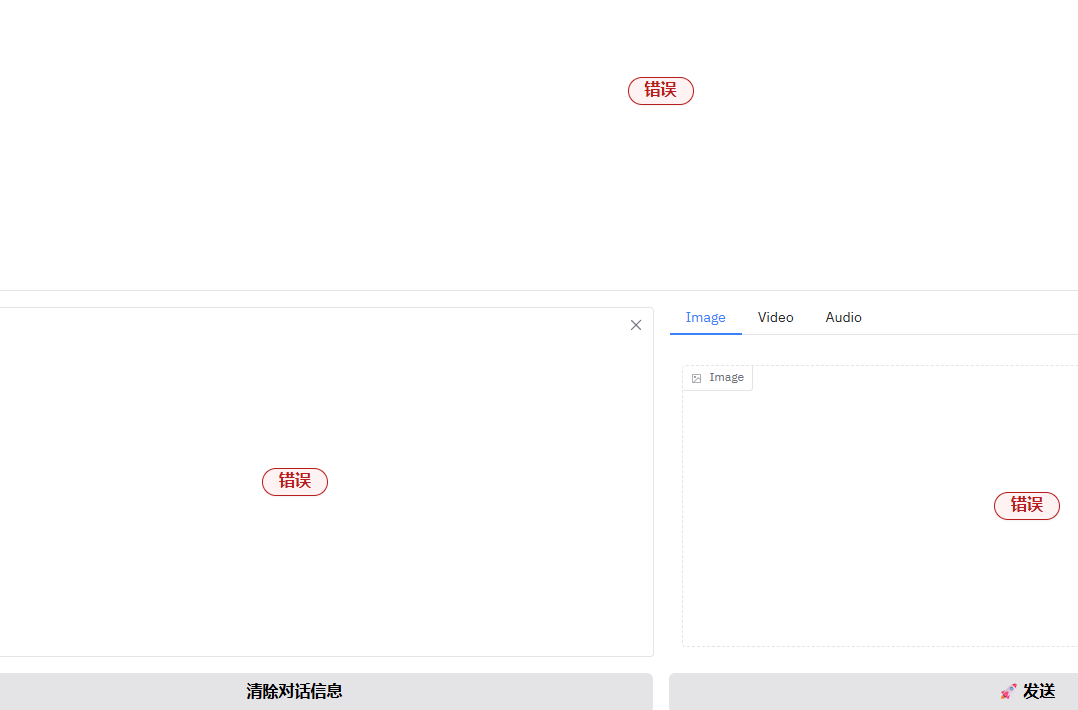
TypeError
果不其然还是报错了。我去后台看了下是数值问题。
<blockquote>
TypeError: ' |









 提升卡
提升卡 置顶卡
置顶卡 沉默卡
沉默卡 喧嚣卡
喧嚣卡 变色卡
变色卡 千斤顶
千斤顶 照妖镜
照妖镜



