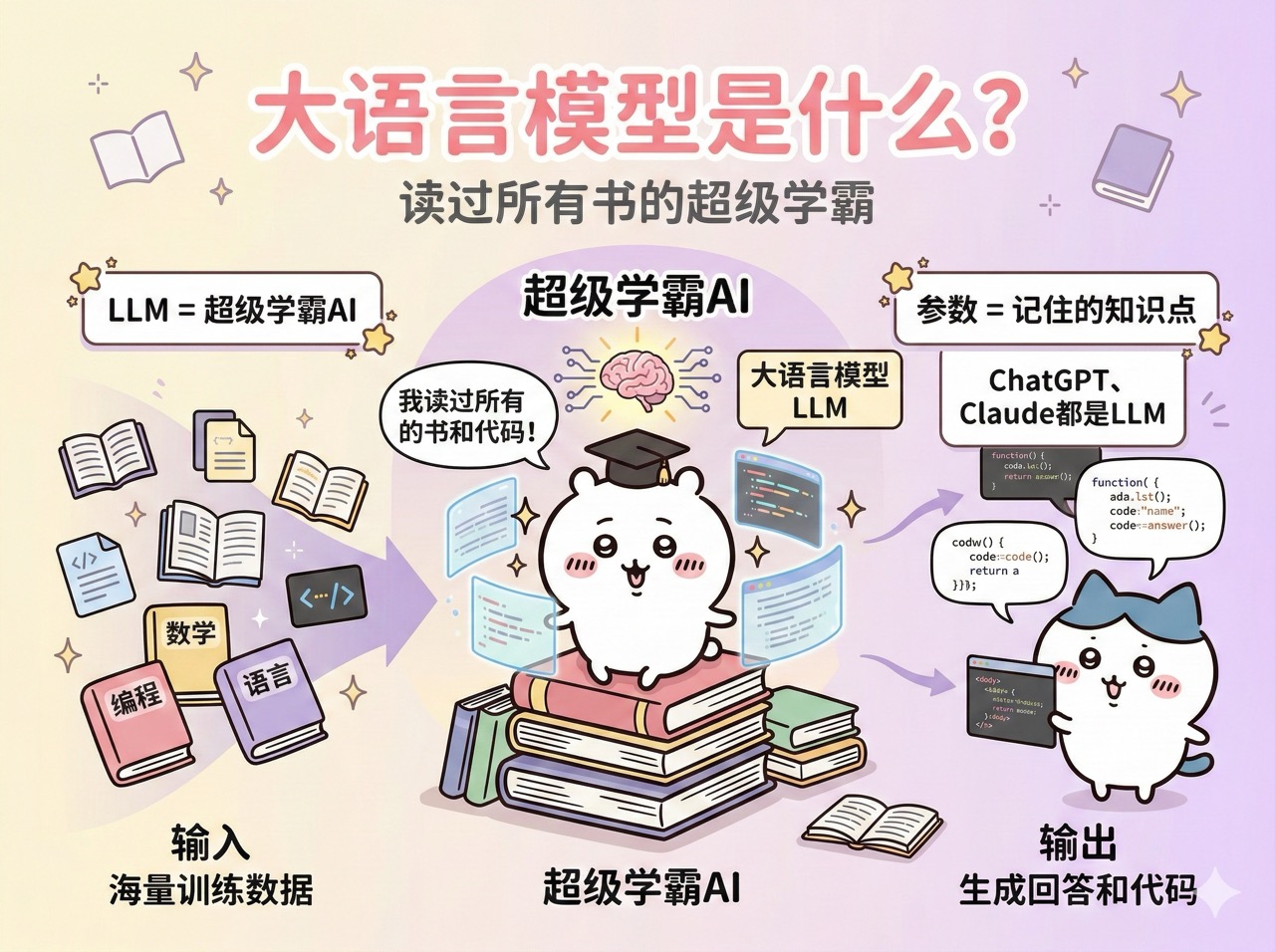
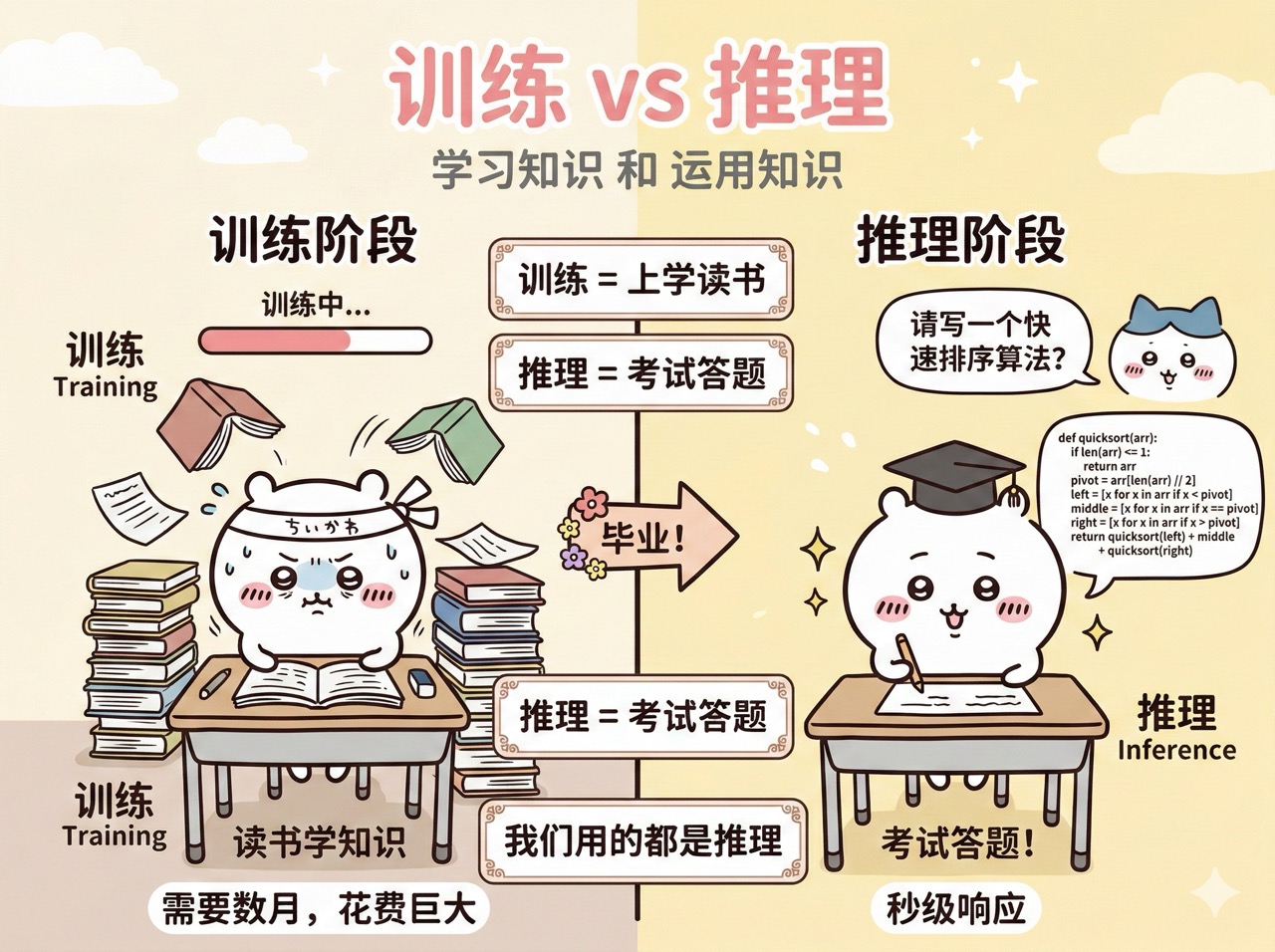
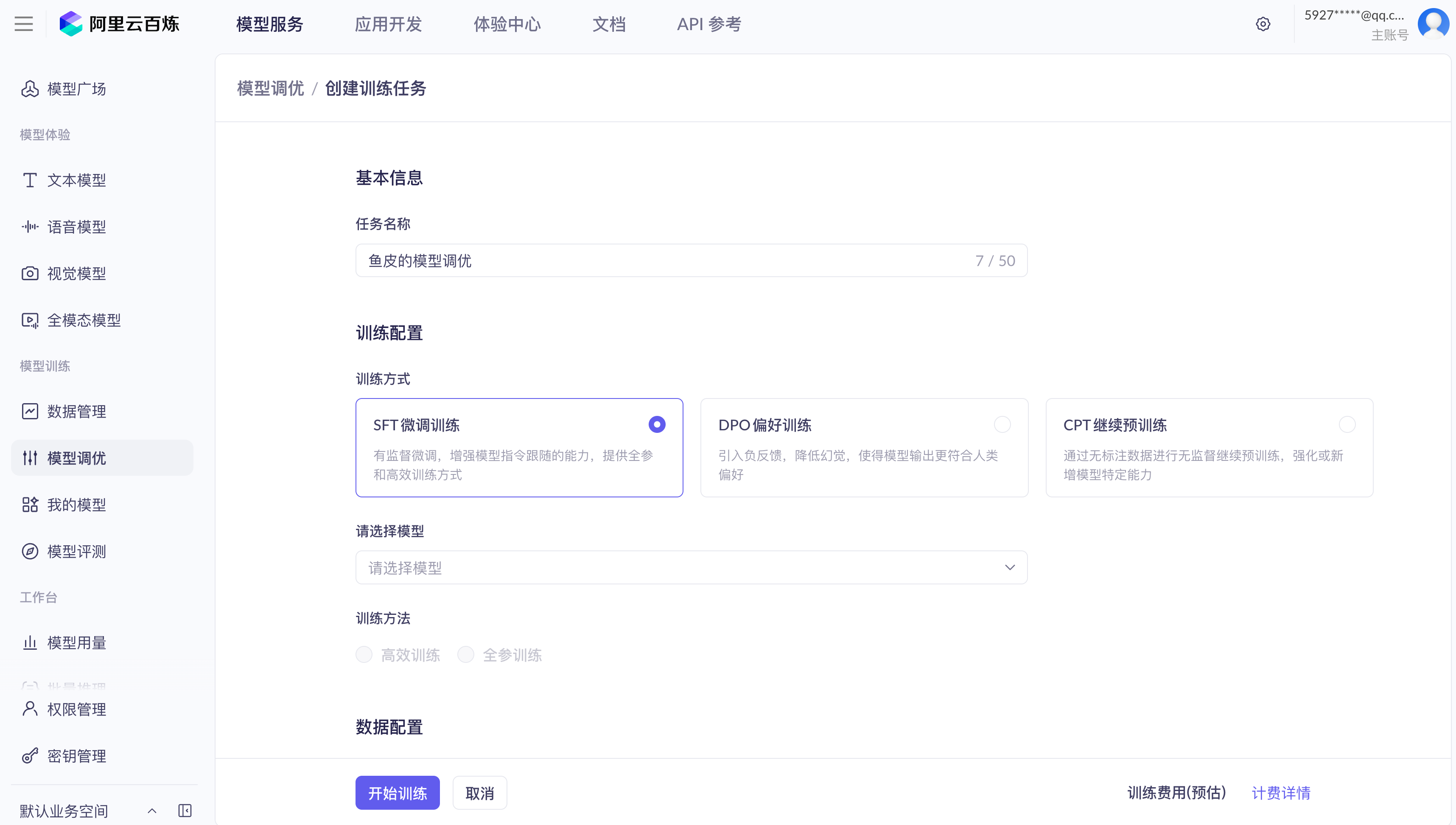
训练(Training)是让 AI 模型从大量数据中学习知识的过程。这个过程需要海量的计算资源和时间,一般由 AI 公司完成。绝大多数情况下,你不需要自己训练模型,直接用训练好的成品就行。
推理(Inference)是模型训练完成、具备了知识之后,用学到的知识来回答问题、生成内容的过程。我们日常使用 AI 工具,比如和 ChatGPT 对话、让 Cursor 写代码,本质上都是 AI 模型在进行推理。
打个比方,训练就像学生上学读书,推理就像学生参加考试答题。
理解这 3 种角色有助于你更好地使用 AI。比如很多 AI 编程工具允许你设置系统提示词来定义 AI 的行为规则,而你在对话框中发送的内容就是用户提示词。
系统提示词
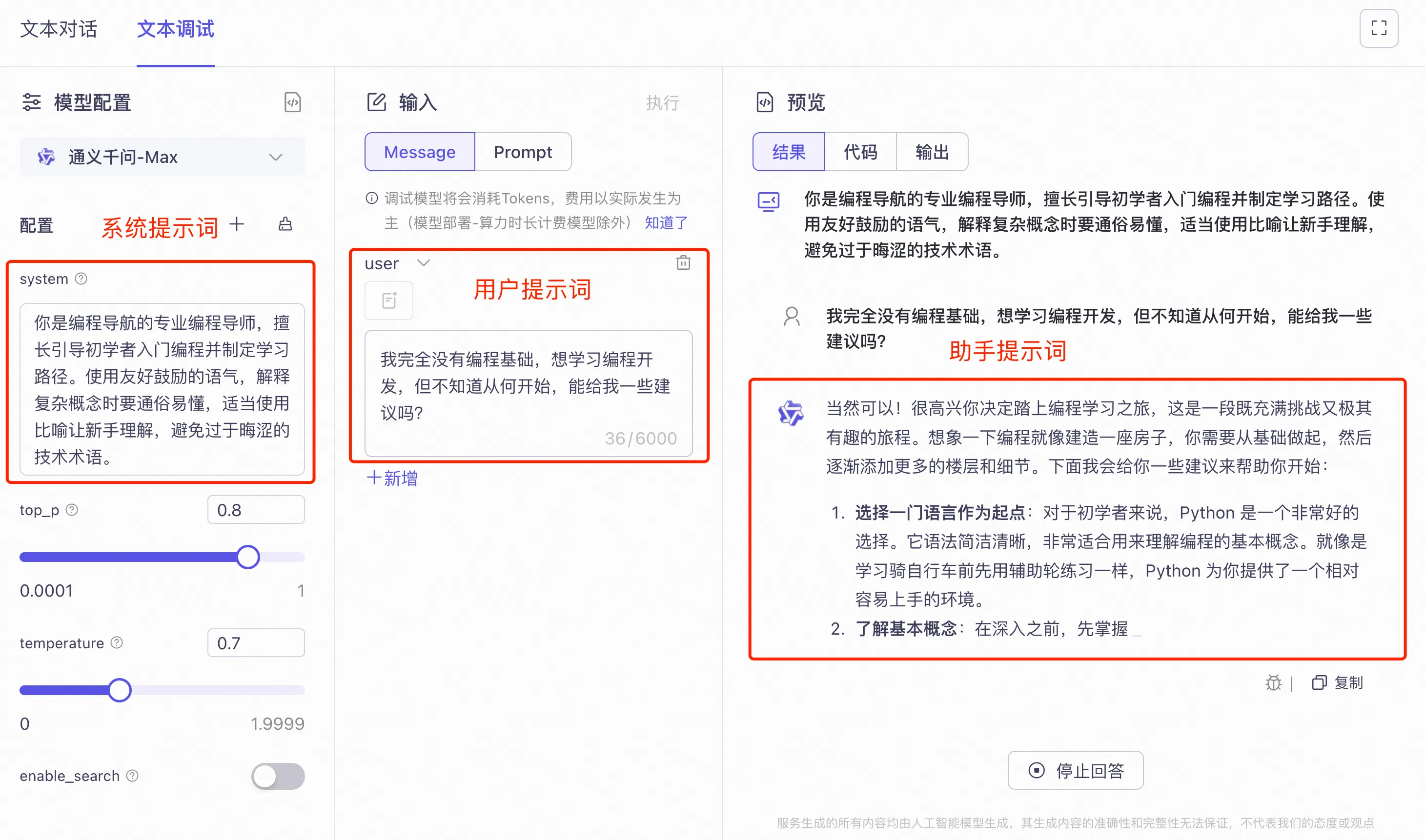
系统提示词(System Prompt)是在对话开始前给 AI 设置的指令,用来定义 AI 的角色、行为和限制。
比如,你可以设置系统提示词:“你是一位资深的 Java 后端开发专家,请用简洁清晰的代码风格回答问题。”
系统提示词在整个对话过程中都会生效,是定制 AI 行为的重要方式。
还记得前几年 AI 刚流行的时候,市面上冒出了一大堆 AI 助手网站么?其实很多就是 “套壳”,底层调用的是同一个大模型,只不过给不同的 AI 助手设定了不同的系统提示词,比如 “你是一个翻译专家”、“你是一个法律顾问” 等。
提示词工程
提示词工程(Prompt Engineering)是设计和优化提示词的技术,目的是让 AI 更好地理解你的意图,生成更符合预期的结果。
这是 Vibe Coding 的核心技能之一。好的提示词工程师能用更少的对话轮次、更低的 Token 成本,让 AI 生成更高质量的代码。
想学习编写提示词的实战技巧,可以看看鱼皮的免费《AI 编程教程》:提示词编写技巧
零样本提示(Zero-shot)
零样本提示是指在给 AI 下达任务时,不提供任何示例,直接描述你的需求让 AI 去完成。
比如:“请把这段英文翻译成中文。”
AI 会根据自己的训练知识来完成任务。
对于简单任务,零样本提示一般就够用了,不需要提供额外的示例内容,还能节约一些 Token 成本。
少样本提示(Few-shot)
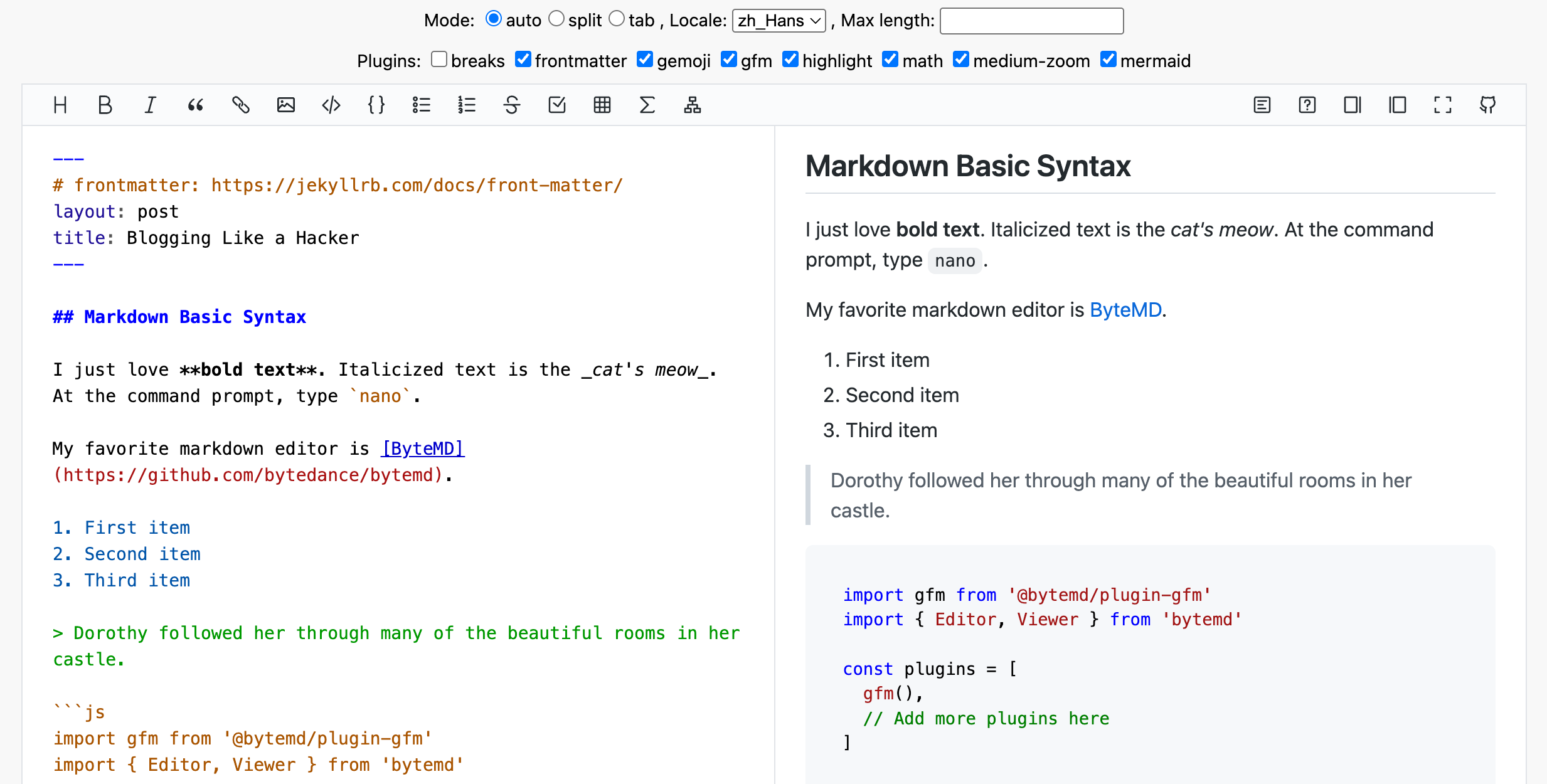
少样本提示是指在给 AI 下达任务时,额外提供几个输入输出的示例,让 AI 通过这些示例学习你想要的格式或风格,从而更准确地完成任务。
比如:
请按以下格式翻译:英文:Hello → 中文:你好英文:Thank you → 中文:谢谢英文:Good morning → 中文:
复制代码
通过提供示例,AI 能更准确地理解你的需求,输出更一致的结果。
思维链提示(Chain-of-Thought)
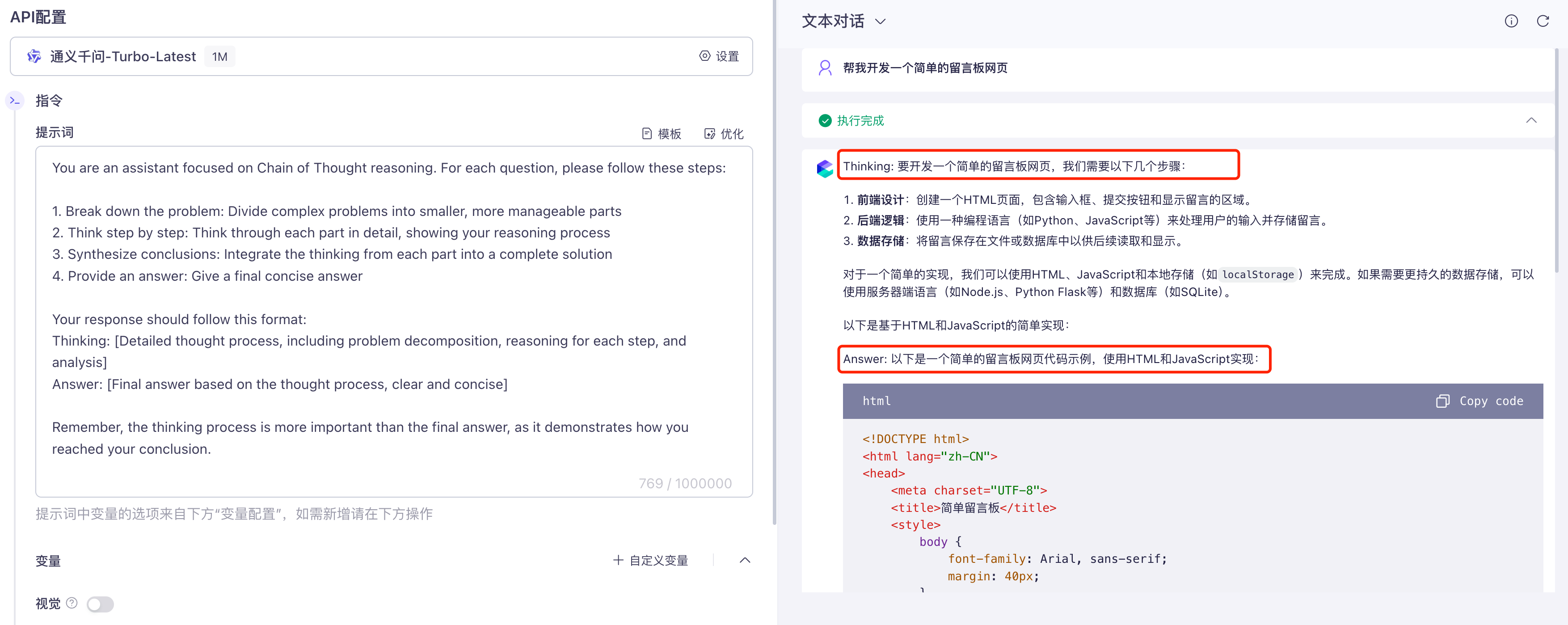
思维链提示(Chain-of-Thought,简称 CoT)是一种引导 AI 展示推理过程、一步一步思考问题的提示技术,而不是让 AI 直接给出答案。这对于复杂的推理任务特别有效,比如多步骤的数学计算、代码逻辑分析、系统架构设计等。
触发思维链提示的方法很简单。很多推理模型(比如 DeepSeek-R1)和 AI 编程工具天然内置了思维链能力,会自动展示推理过程。你也可以在提示词中手动加上 “请一步一步思考”,AI 就会展示它的推理过程,一般能得到更准确的答案。
在 AI 编程中,涉及复杂业务逻辑、多模块交互、或者需要权衡多种技术方案的项目,特别适合利用推理模型和思维链提示能力,让 AI 想清楚再动手。
Agentic Coding 智能体编程是指让 AI 像一个自主的 “智能体”(Agent)一样工作,能够自己规划任务、执行操作、验证结果,而不只是被动地回答问题。
它和前面提到的 Agentic Engineering 的区别在于,Agentic Coding 强调的是 AI 的自主执行能力(AI 能干什么),而 Agentic Engineering 强调的是人对 AI 的管理方法论(人该怎么管)。
如今,几乎所有主流 AI 编程工具都提供了智能体编程的能力。比如在 Cursor 的 Agent 模式中,AI 可以:
自动读取和分析多个文件
规划实现方案
执行代码修改
运行测试验证
自动修复问题
这比传统的问答式 AI 更强大,因为它能自主完成复杂的多步骤任务。可以说,AI 不再只是辅助编程的配角,而是正在成为项目开发的核心驱动力。
多智能体协作
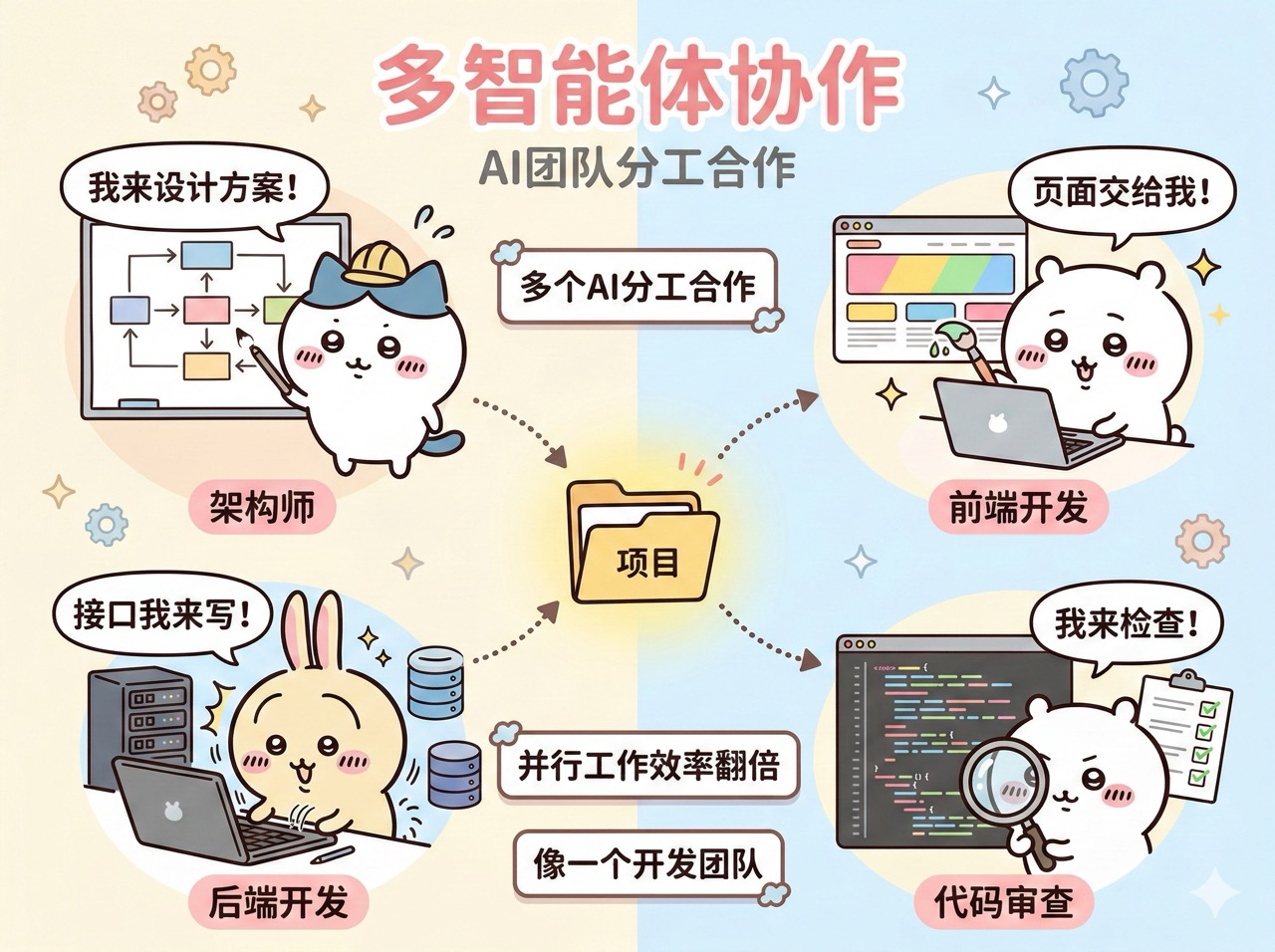
多智能体协作(Multi-Agent)是指多个 AI 智能体分工合作,共同完成复杂任务。
比如,一个智能体负责设计架构,一个负责写前端代码,一个负责写后端代码,一个负责代码审查。它们像一个软件开发团队一样协作。
这两年,多智能体系统正在成为 AI 编程的重要趋势。它的优势不仅仅是能处理更复杂的项目,还能通过并行工作大幅提升效率,让原本需要几小时的任务在几分钟内完成。
智能体编排
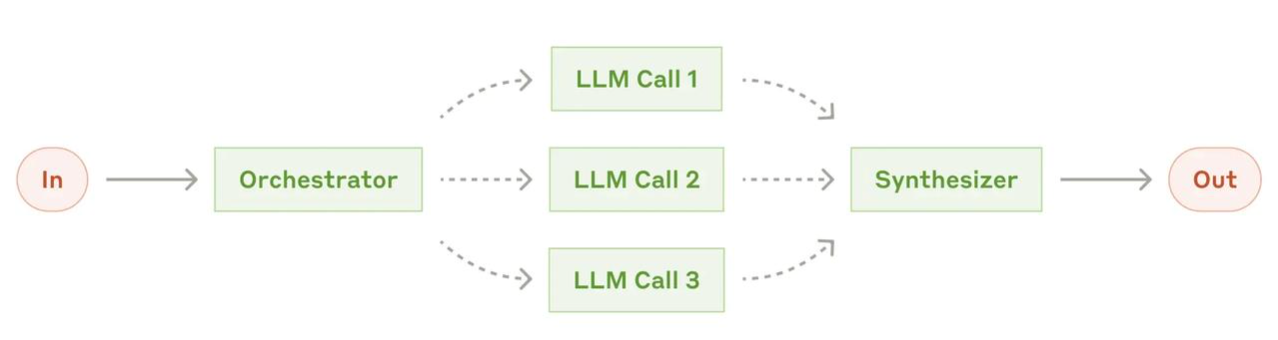
编排(Orchestration)是指协调和管理多个 AI 智能体或 AI 任务的过程,确保它们按正确的顺序和方式工作。
如果说多智能体协作关注的是 “有哪些角色参与”,那编排关注的是 “谁先干、谁后干、结果怎么汇总”,它是多智能体系统的指挥中枢。
就像乐队指挥一样,编排器决定哪个智能体在什么时候做什么事情、如何传递信息、如何汇总结果。
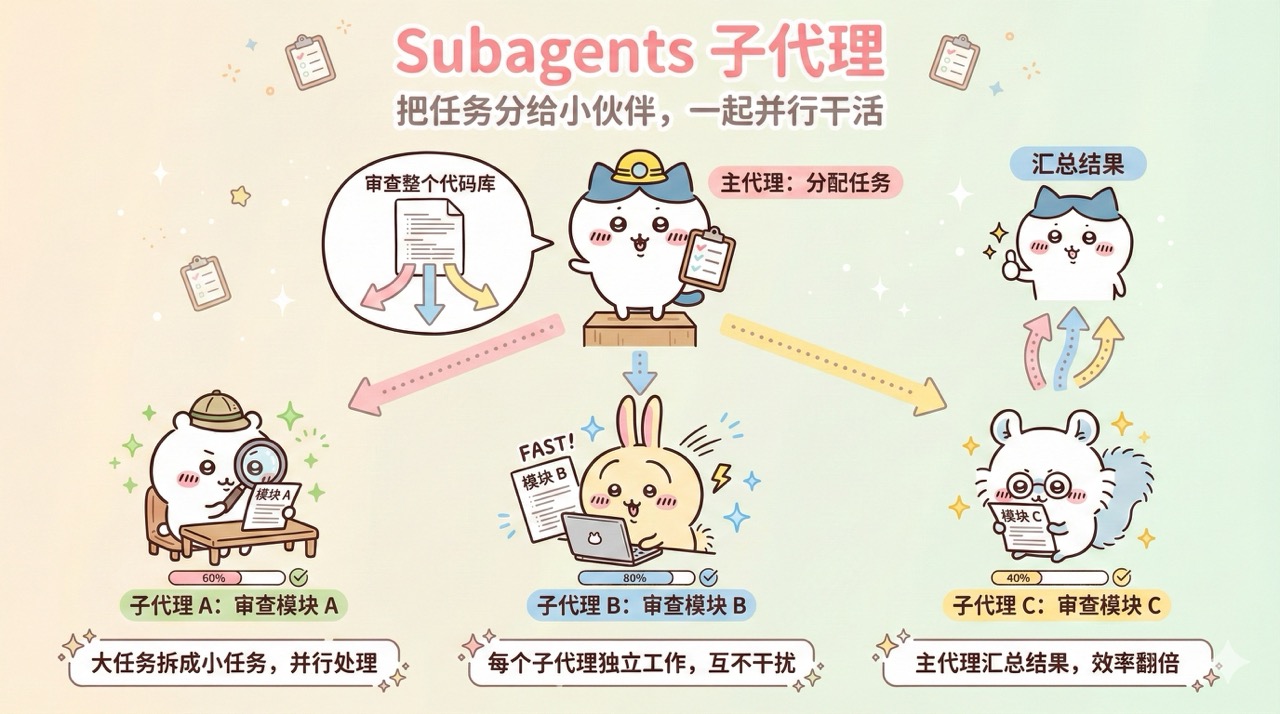
Subagents 子代理
Subagents(子代理)是指主 AI 智能体将部分任务分派给独立的子智能体来并行处理的机制。
你可以把它理解成 AI 的下属,就像一个经理把活分给手下的几个员工同时干一样。当主 AI 遇到一个大任务时,它可以把独立的小任务分给几个子代理同时干,自己继续处理其他工作。
Subagents 的好处是:
并行处理多个独立任务,效率翻倍
主代理的上下文保持干净,不会被子任务的细节污染
每个子代理可以专注于自己的任务,结果更准确
比如你可以让几个子代理同时审查代码库的不同模块,速度会快很多。
在 Claude Code 中,AI 会通过内置的 Task 工具自动生成子代理来处理子任务,你不需要做额外配置。你也可以在 .claude/agents/ 目录下创建自定义的子代理(用 Markdown 文件定义),给它指定专属的角色描述、工具权限和行为规则。
不过子代理也有局限,每个子代理的上下文是独立的,它们之间无法直接共享信息,所以不适合有强依赖关系的任务。另外,多个子代理同时运行会消耗更多 Token,成本会相应增加。就像公司招人一样,多招几个人确实能干得更快,但工资支出也得跟着涨,而且人多了沟通协调的成本也会上来。
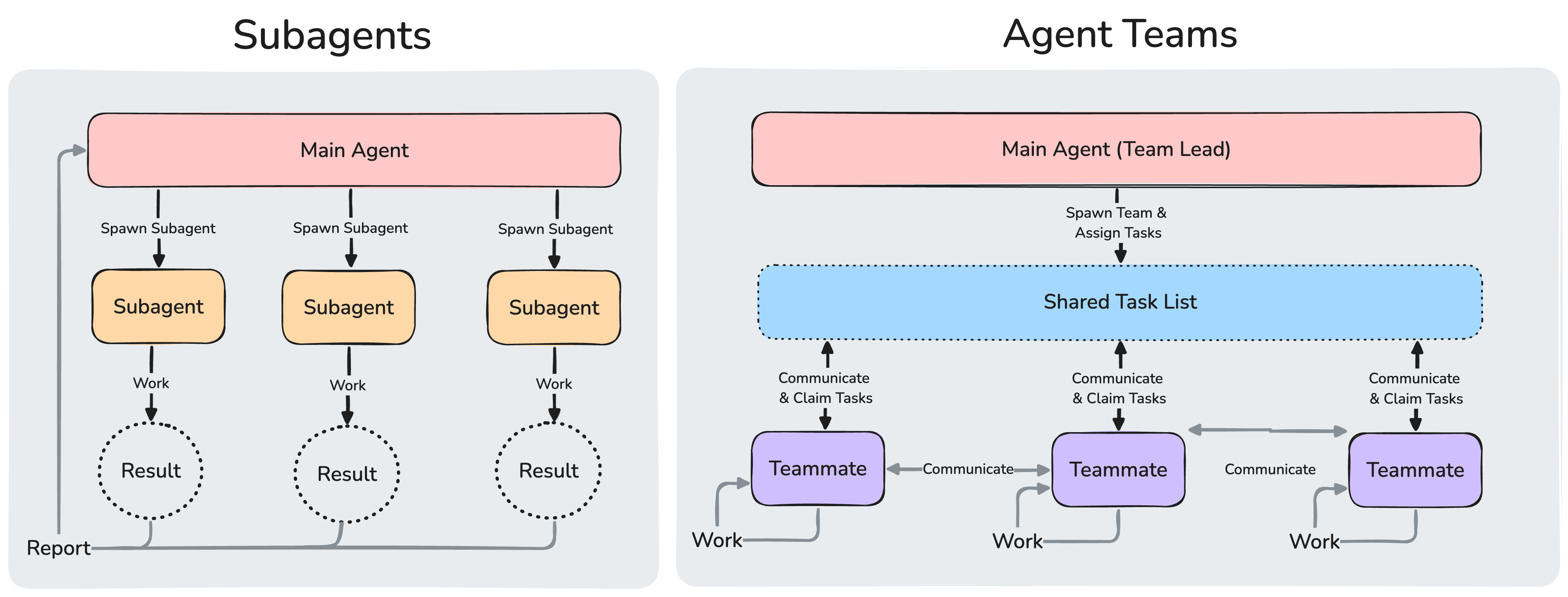
Agent Teams 智能体团队
Agent Teams(智能体团队)是 2026 年兴起的多智能体编程新模式,由 Claude Code 率先推出。它让 3 ~ 5 个独立的 AI 智能体组成团队,在同一个项目上并行工作。
和传统的单 AI 对话不同,Agent Teams 中有一个 Team Lead(队长)负责拆解任务和协调工作,其他 Teammates(队员)各自领取任务独立执行,还能通过消息系统互相沟通。
后台 Agent(Background Agent)是让 AI 在后台自主运行、完成任务后再通知你结果的能力。
传统的 AI 编程需要你盯着屏幕等 AI 一步步做完,电脑还不能关。而后台 Agent 允许你把任务交给 AI 后,就去做别的事情,AI 会在云端独立完成工作,你甚至可以关掉电脑!
比如让 AI 在后台修复一批 Bug、跑一轮代码审查、或者完成一个完整的功能模块,做完了会通知你来验收。
目前 Claude Code、Cursor 等工具都已经支持后台 Agent 能力。以后 AI 编程可能就像发微信一样,你在手机上把需求发过去,该干嘛干嘛,等 AI 做完了来找你验收就行。
Agent Loop 智能体循环
Agent Loop(智能体循环)是 AI 智能体的核心工作机制,简单来说就是 AI 通过不断重复 “感知-思考-行动-观察” 的循环来一步步完成任务。
一个典型的 Agent Loop 包括:
感知:获取当前环境信息(读取文件、查看错误等)
思考:分析情况,决定下一步行动
行动:执行具体操作(写代码、运行命令等)
观察:检查行动的结果
循环:根据结果决定是否继续
这个循环会一直进行,直到任务完成或达到终止条件。
理解 Agent Loop 能帮你更好地规划任务和管理 AI 的工作过程。需要特别注意的是,AI 编程时 Agent Loop 的循环次数不要太多,很多工具都有最大循环次数限制,循环太多不仅效果不好,还会疯狂烧 Token!有朋友一觉醒来发现额度用光了,就是因为让 AI 陷入了无限循环……
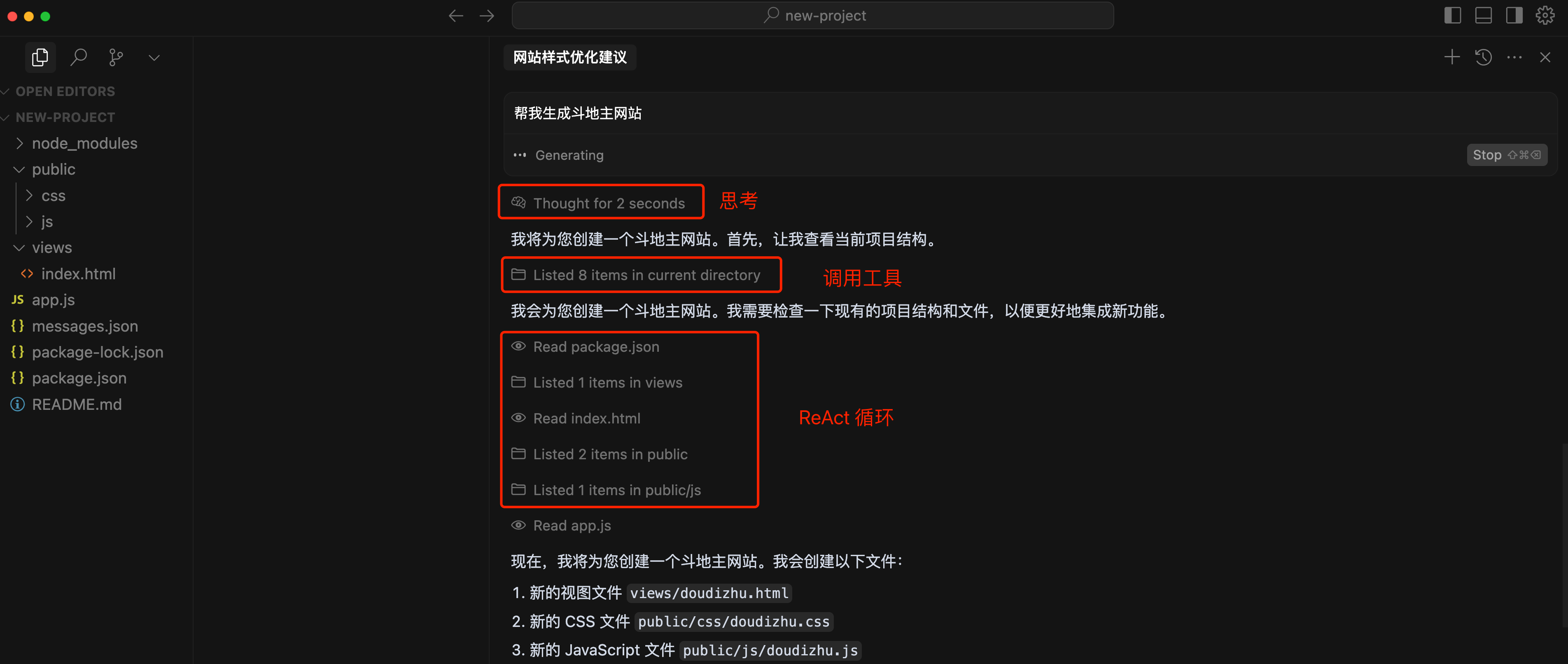
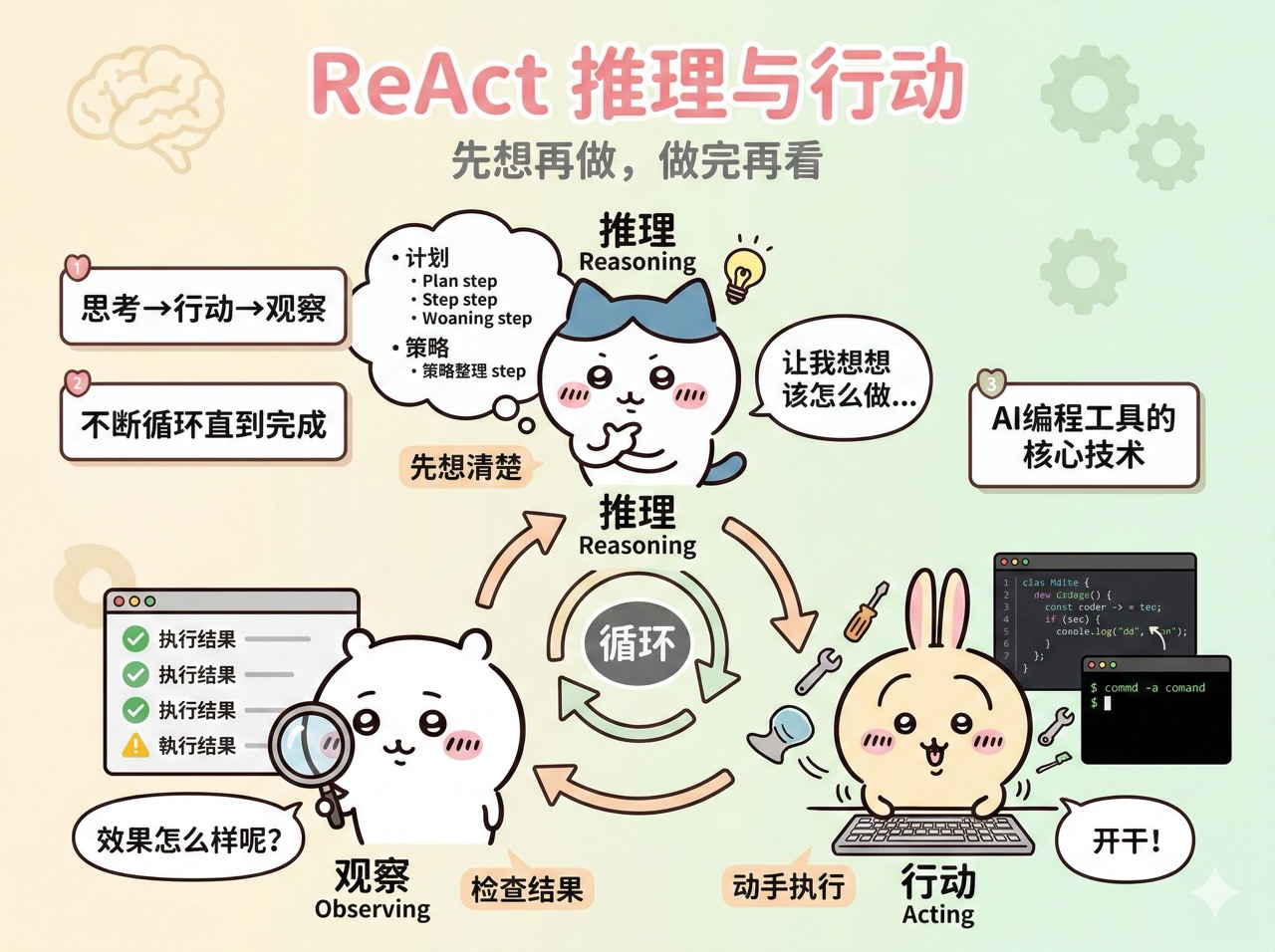
ReAct 推理与行动
ReAct(Reasoning and Acting)是一种让 AI 智能体交替进行推理和行动的技术范式。它的核心思想很简单:让 AI 先想清楚再动手,动完手再看看效果,然后继续想下一步怎么做。
传统的 AI 要么只思考不行动,要么只行动不思考。而 ReAct 让 AI 能够:
先推理:思考当前情况,制定计划
再行动:执行具体操作
观察结果:看看行动效果如何
继续推理:根据结果调整策略
这种 “思考 - 行动 - 观察” 的循环让 AI 能更可靠地完成复杂任务,是现代 AI 编程工具的核心技术之一。
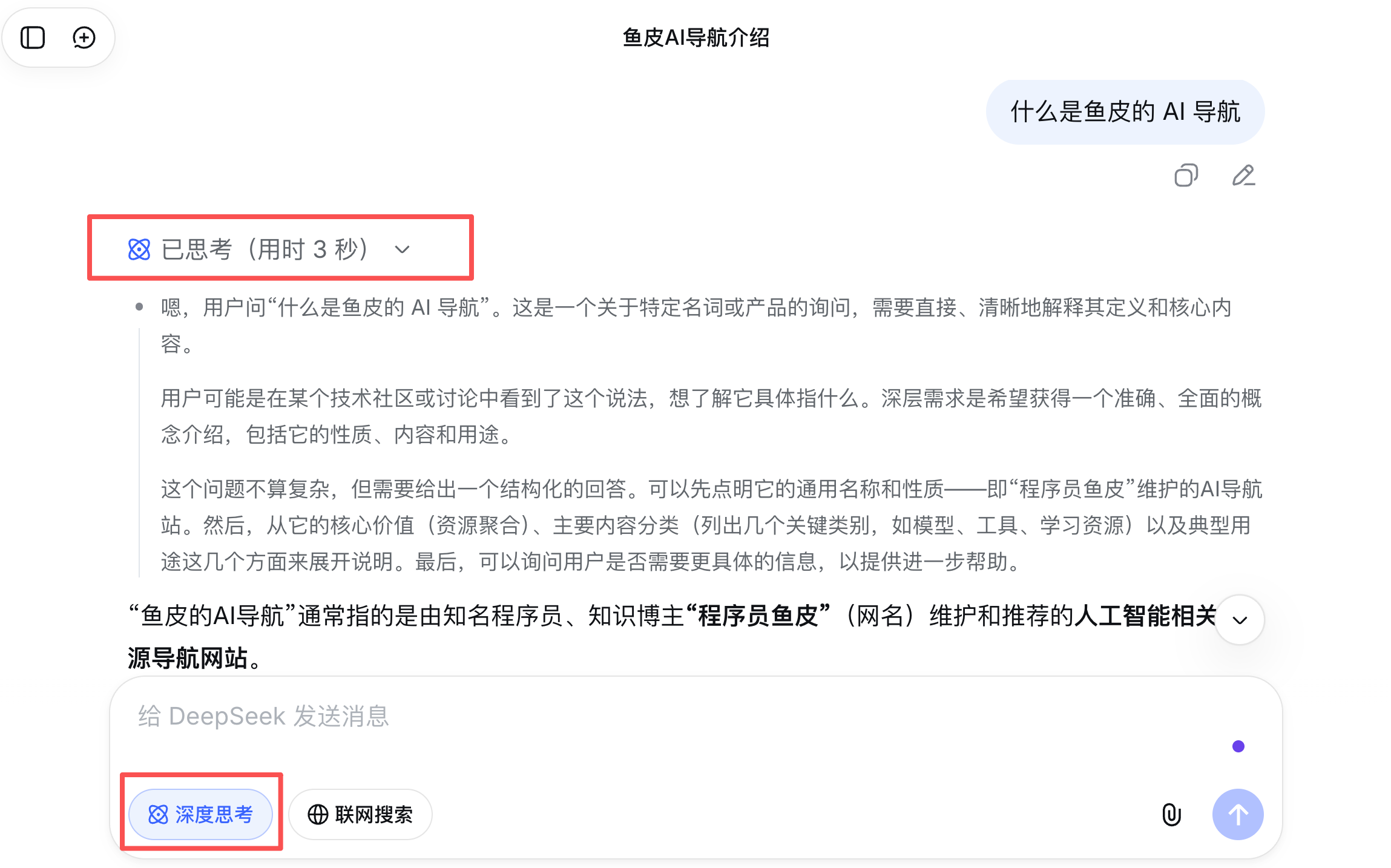
深度思考
深度思考(Deep Thinking)是让 AI 在回答之前先进行一段内部推理的能力,也叫 “扩展思考” 或 “思考模式”。
它和前面提到的思维链提示(CoT)有什么区别呢?
思维链提示是一种提示词技巧,通过提示词引导 AI 展示推理过程;而深度思考是模型内置的能力,AI 会在内部自动进行深度推理,不需要你在提示词中特别要求。
普通模式下,AI 收到问题后会直接生成回答。而开启深度思考后,AI 会先在内部进行一系列推理步骤,比如分析问题、考虑多种方案、评估利弊,然后才输出最终答案。你有时能在 AI 的回复中看到一个 “思考中...” 的过程,那就是深度思考在工作。
深度思考特别适合复杂的编程任务,比如设计系统架构、排查难以定位的 Bug、优化算法等。代价是速度更慢、Token 消耗更多。
目前主流 AI 模型和 AI 编程工具都支持深度思考,并且你可以选择是否开启思考模式。
自适应思考
自适应思考(Adaptive Thinking)是深度思考的智能化版本,让 AI 自动判断当前问题需要多深的思考程度。
以前深度推理模式只能手动开关,开了的话简单问题也慢吞吞地想半天、还浪费钱,关了的话复杂问题又容易出错。
AI 有了自适应思考能力后,可以做到简单问题秒回,复杂问题会自动进入深度思考模式。这样既保证了质量,又节省了时间和成本。
Anthropic 在 Claude Opus 4.6 中率先引入了自适应思考能力,开发者可以设置不同的思考力度级别来平衡质量和成本。
工具调用
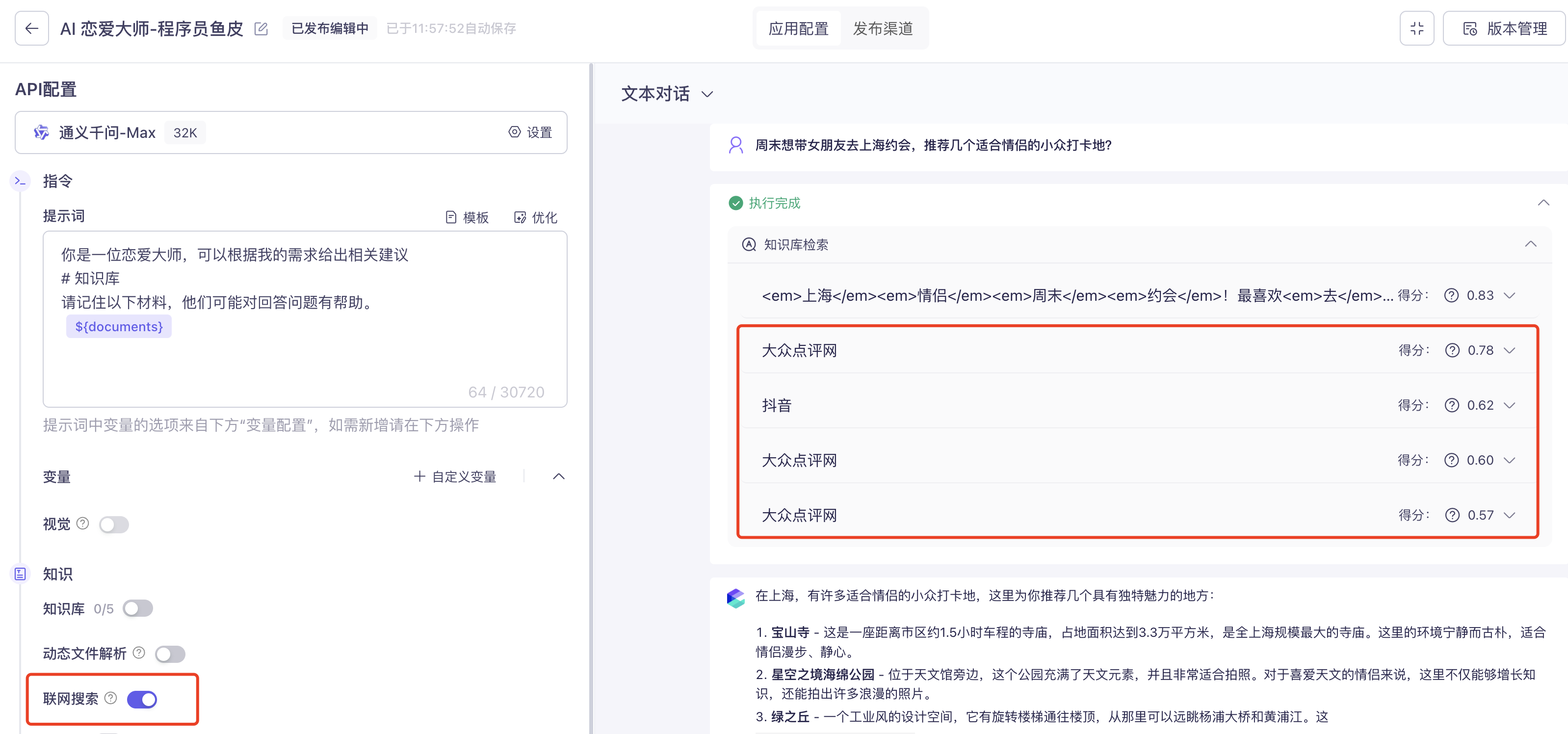
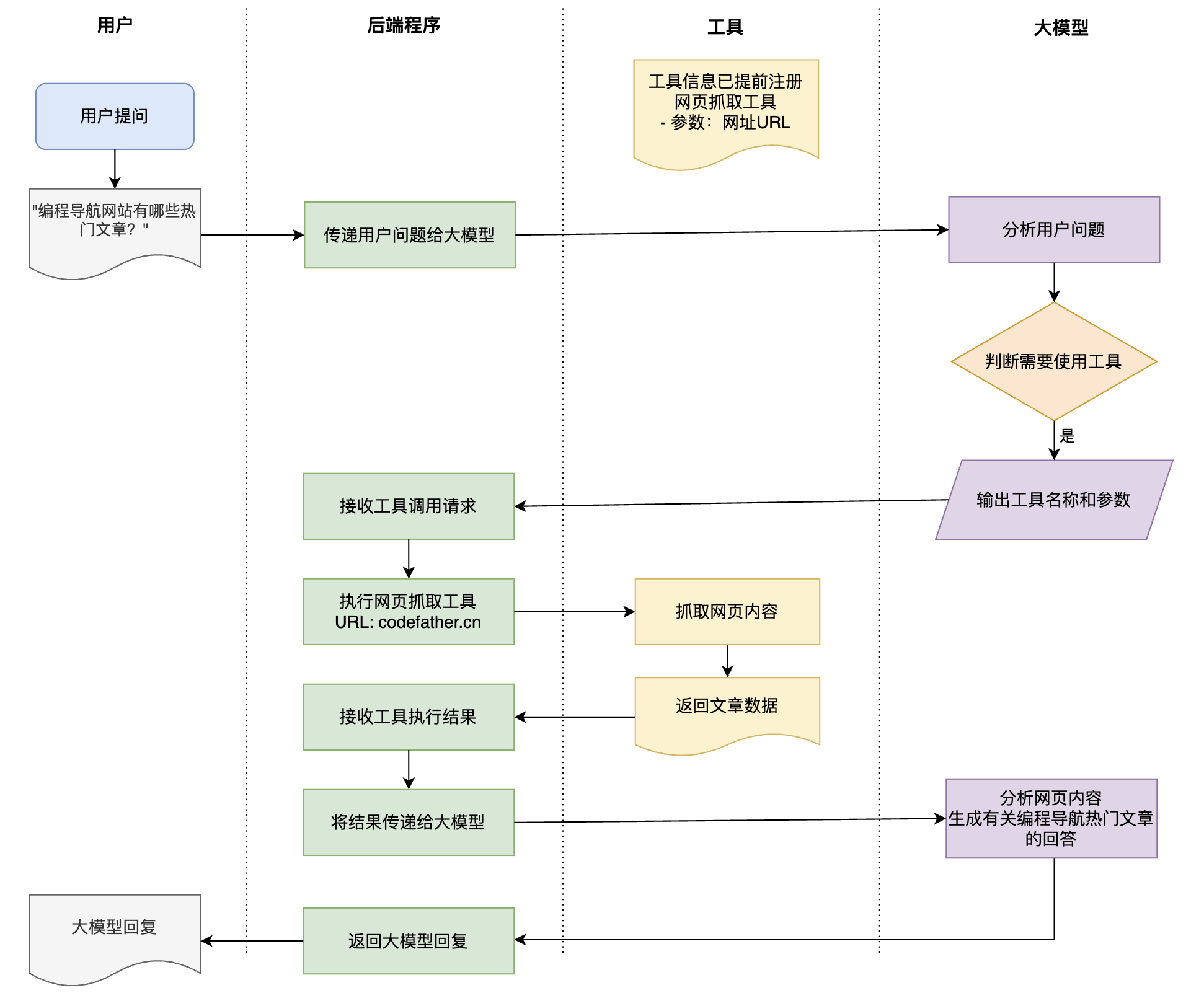
工具调用(Tool Use / Function Calling)是让 AI 能够使用外部工具和功能的技术。
AI 本身只能生成文字,但通过工具调用,它可以读写文件、搜索网页、执行命令和脚本、调用 API、操作数据库等等。
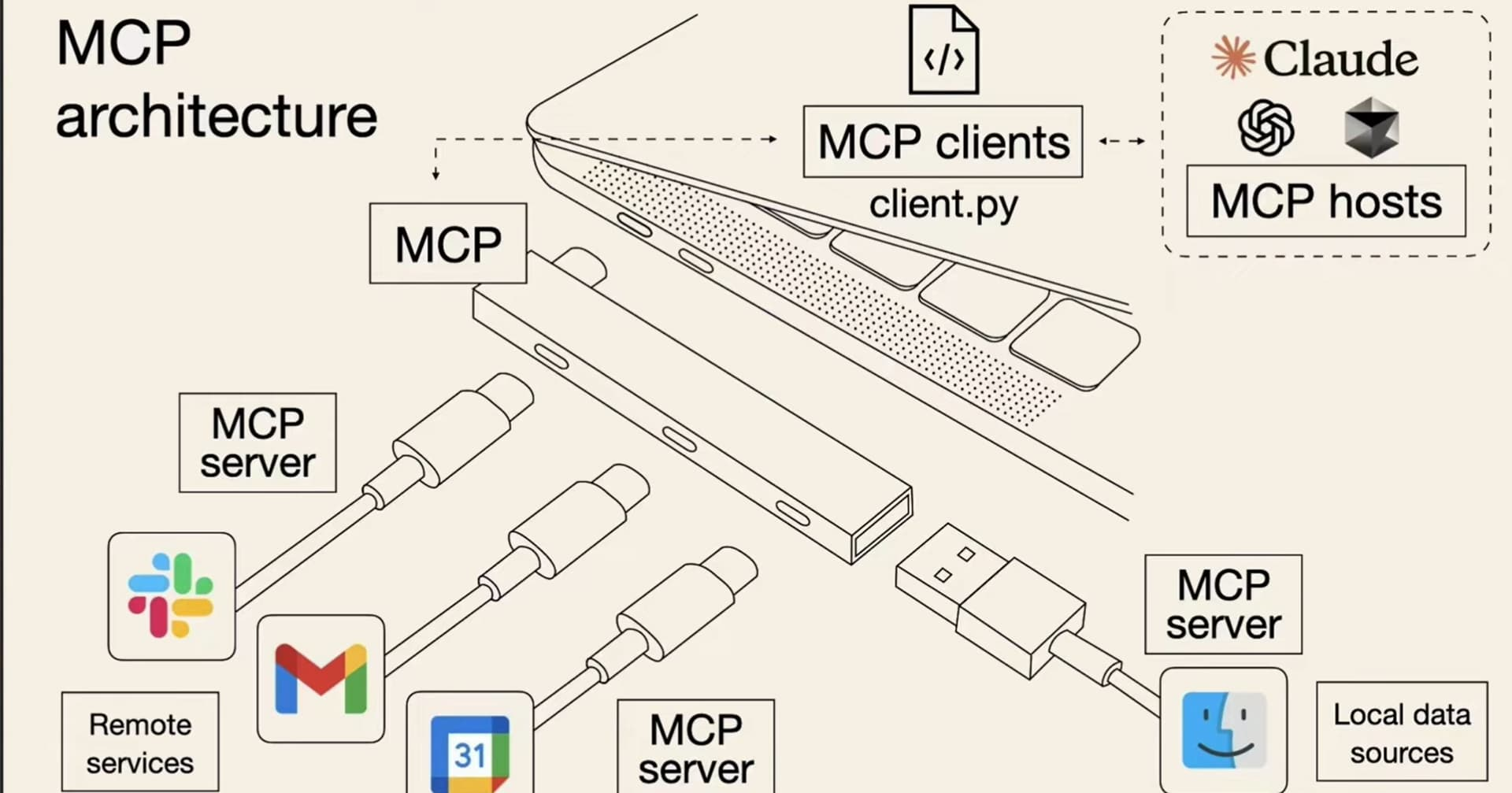
MCP(Model Context Protocol)是 Anthropic 在 2024 年底推出的开放标准,用于让 AI 模型安全地连接外部数据源和工具。
你可以把 MCP 理解成 AI 世界的 “USB 接口”。就像 USB 接口让各种设备(键盘、鼠标、U 盘)都能用同一种方式连接电脑一样,MCP 让各种外部工具(文件管理、数据库、搜索引擎等)都能用同一种方式连接 AI,不用为每个工具单独写一套对接代码。
MCP 的核心价值在于 标准化。开发者不需要为每个 AI 工具单独开发连接器,只需要按照 MCP 标准开发一次,就能被所有支持 MCP 的 AI 工具使用。目前 Claude Code、Cursor、Windsurf 等主流 AI 编程工具,以及各种网页 AI Agent 应用都已经支持 MCP 协议。
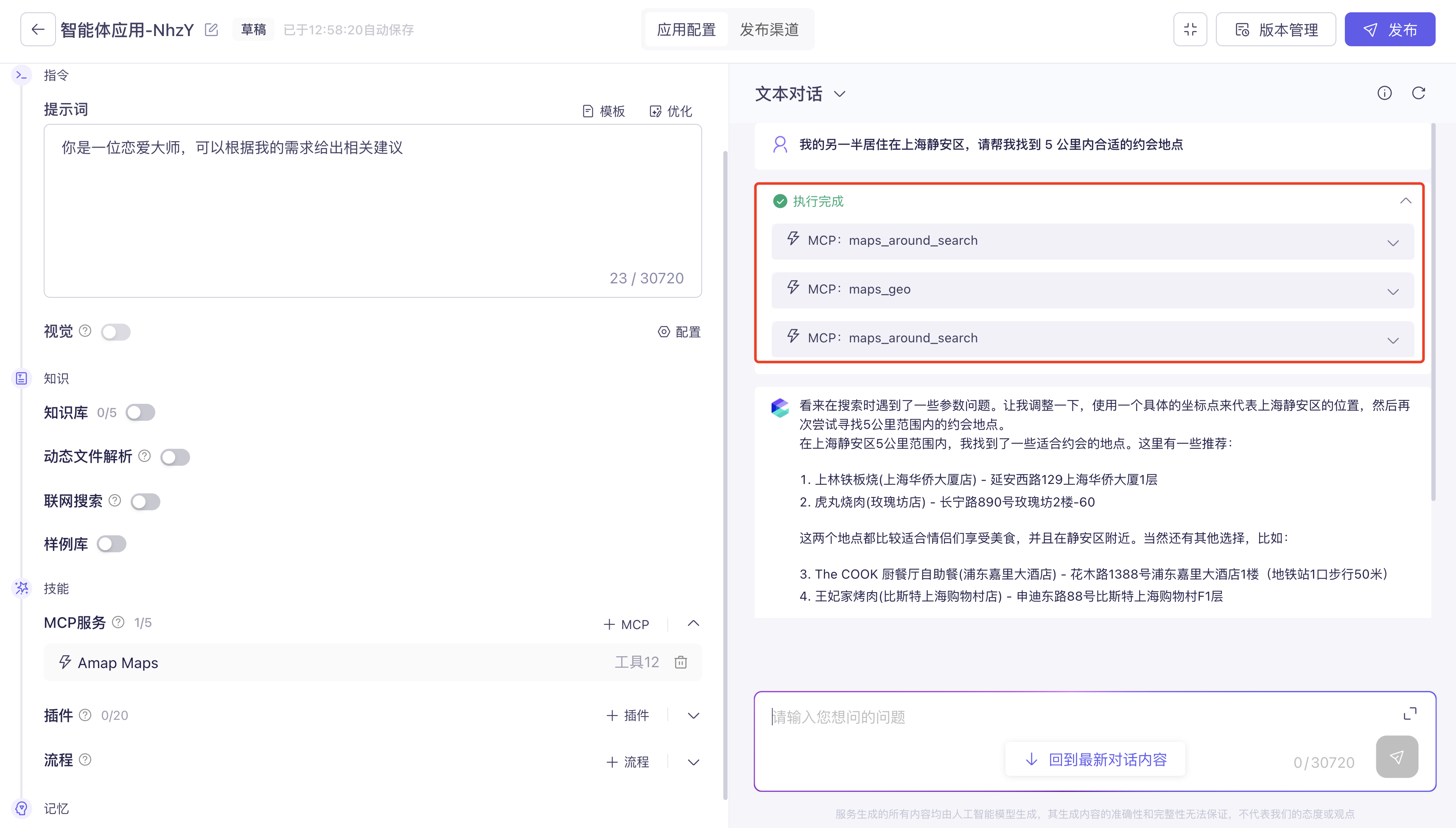
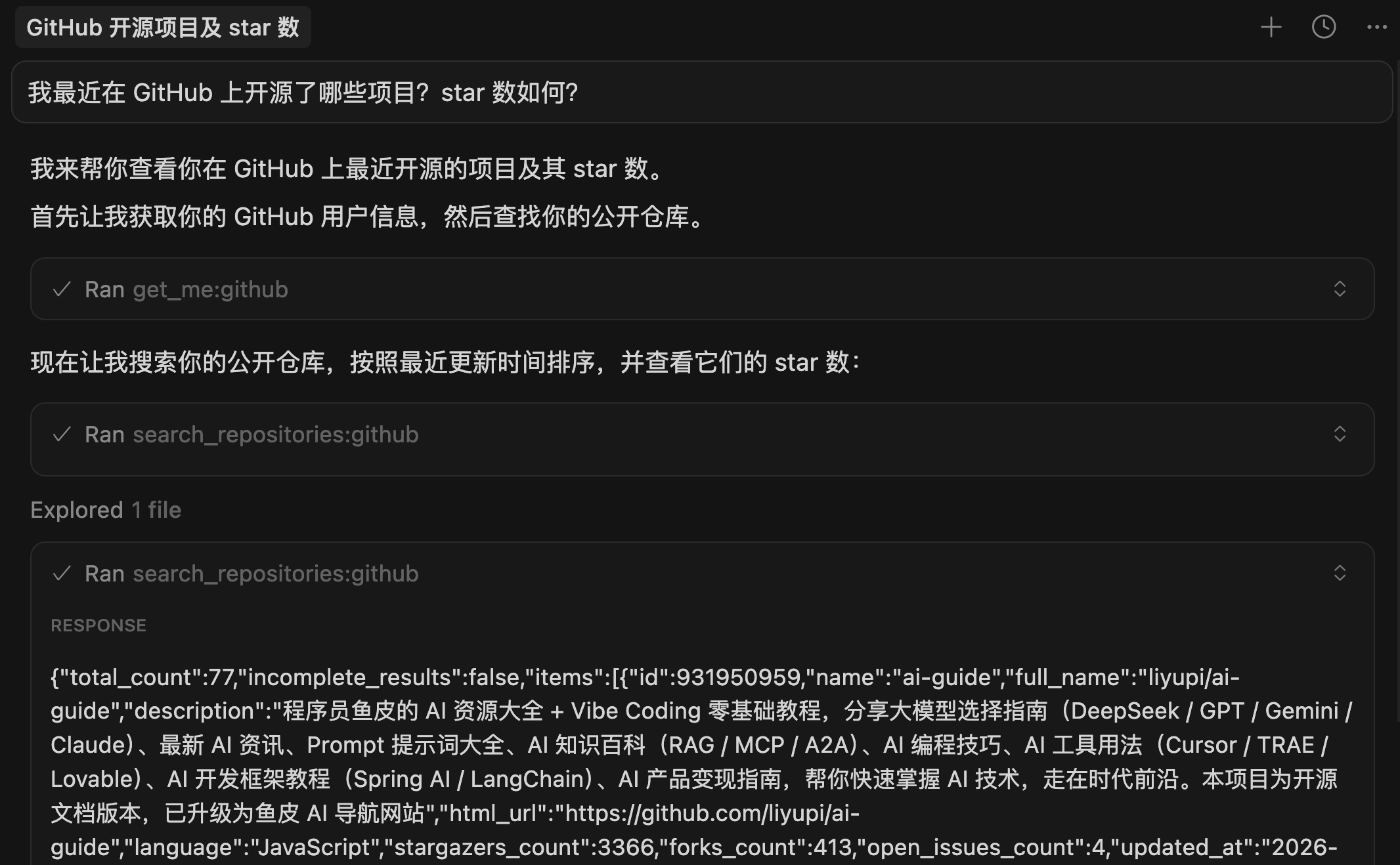
在 Vibe Coding 中,MCP 让 AI 能够连接更多外部工具和数据源,大大扩展了 AI 的能力边界。比如通过 Figma MCP,AI 可以直接读取设计稿并生成对应的网页代码;通过 GitHub MCP,AI 可以直接操作代码仓库、创建 PR;通过数据库 MCP,AI 可以查询和分析业务数据。






 提升卡
提升卡 置顶卡
置顶卡 沉默卡
沉默卡 喧嚣卡
喧嚣卡 变色卡
变色卡 千斤顶
千斤顶 照妖镜
照妖镜



