一、相关定义1、SLI、SLO、SLA是什么SLI:Service Level Indicator,是服务等级指标的简称,她是衡量系统稳定性的指标。 SLO:Service Level Objective,服务等级目标的简称,也是我们设定的稳定性目标。 SLA:服务等级协议,假如是给第三方做的网站,并签订了协议SLO达不到99.999%就赔偿多少钱,那么根据计算出的SLO,再根据签订的SLA协议,算出补偿的金额。 2、如何选择SLI在系统中,常见指标有以下几种:
那我们选取指标只需要遵循两个原则:1)选择能标识一个主体是否稳定的目标。2)优先选择与用户体验强相关或用户可以明显感知的指标。 我们可以直接套用Google的方法:VALET(Volume容量/流量、Availability可用性、Latency延迟、Error错误、Ticket故障单)。这是Google提出的服务等级指标选择框架,通过5个核心维度帮技术团队系统性地衡量服务稳定性,未设定服务等级目标提供清晰的指标体系。 (1)Volumn容量/流量核心含义:衡量服务地承载能力或业务规模,即服务在单位时间内可处理的最大请求量或数据量。 关键指标:
应用场景:日常运维时设定常规流量下的容量基线(如日常QPS不低于1000);大促/峰值场景,针对双11等流量高峰,指定扩容后的容量目标(如大促期间QPS峰值不低于5000) [code](1)QPS,每秒查询量 能衡量系统处理简单请求的速度(比如打开网页、搜索商品等),数字越大说明系统响应快,能同时相应更多小请求。 (2)TPS,每秒事务量 QPS是但此请求,TPS一整套完整操作(如从选餐到结账的全流程)。作用是衡量系统“处理复杂业务”的能力,数字越大,说明系统能同时搞定更多复杂业务。 (3)并发连接数 衡量系统“同时维持多少个活跃用户”的能力(比如1000个用户同时打开APP但没操作,也算连接中)。 (4)会话数 衡量系统同时处理多少个独立用户会话的能力(如登录APP后,系统会生成一个会话ID,只要没退出,这个会话就持续存在)[/code](2)Availability可用性核心含义:衡量服务的正常运行状态,即服务成功响应请求比例。 关键指标:
应用场景:直接关联用户体验,如99.99%的请求返回非5xx状态码(即四个九可用性目标);业务连续性保障,通过监控可用性,及时发现服务中断或降级问题。 (3)Latency延迟核心含义:衡量服务的响应速度,即请求从发出到收到响应的时间,直接影响用户体验。 关键指标:
应用场景:避免平均时延陷阱,由于时延发呢不呈正态分布(少数请求可能极快或极慢),通常用分位数而非平均值来设定目标,更准确反应用户真实体验。 (4)Errors错误核心含义:衡量服务的错误发生频率,包括系统错误和业务逻辑错误。 关键指标:
应用场景:系统错误需优先修复,业务错误需结合产品逻辑优化;设定容错目标,例如5xx错误率<=0.005%。 (5)工单(Tickets)核心含义:衡量服务的自动化程度,即服务异常时需要人工介入的频率,反映系统的自愈能力。 关键指标:
应用场景:
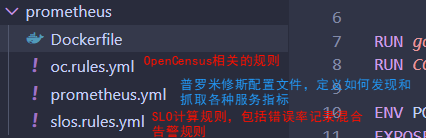
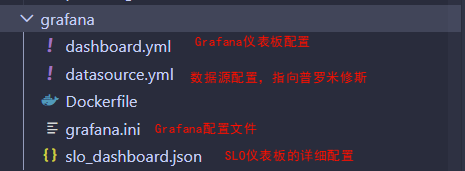
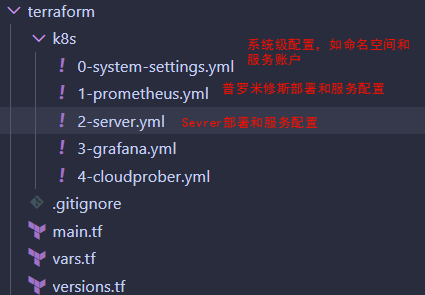
二、开源方案学习1、开源方案1:https://github.com/google/prometheus-slo-burn-example (1)项目各模块
(2)启动步骤 ① 安装kubectl:https://kubernetes.io/docs/tasks/tools/install-kubectl-windows/#install-kubectl-binary-on-windows-via-direct-download-or-curl
② 本地启动服务 & Docker启动服务
【ps】若想一次性启动所有服务,可以查找项目根目录是否有docker-compose.yml文件,若有则可以直接docker-compose up。这将同时启动所有相关服务,并自动配置它们之间的网络连接。这种方式比完整的 Kubernetes 部署更轻量,适合开发和测试用途。
2、开源方案2:https://github.com/slok/sloth?tab=readme-ov-file 编写一个simple-example.yaml。 [code]version: "prometheus/v1" service: "myservice" labels: owner: "myteam" repo: "myorg/myservice" tier: "2" slos: # We allow failing (5xx and 429) 1 request every 1000 requests (99.9%). - name: "requests-availability" objective: 99.9 description: "Common SLO based on availability for HTTP request responses." sli: events: error_query: sum(rate(http_request_duration_seconds_count{job="myservice",code=~"(5..|429)"}[{{.window}}])) total_query: sum(rate(http_request_duration_seconds_count{job="myservice"}[{{.window}}])) alerting: name: MyServiceHighErrorRate labels: category: "availability" annotations: # Overwrite default Sloth SLO alert summmary on ticket and page alerts. summary: "High error rate on 'myservice' requests responses" page_alert: labels: severity: pageteam routing_key: myteam ticket_alert: labels: severity: "slack" slack_channel: "#alerts-myteam"[/code]这是Sloth的SLO定义文件,用来描述我们想要为服务设置的可靠性目标。
go run cmd/sloth/main.go generate -i simple-example.yaml。这样就可以生成完整的 Prometheus 规则集,包括 SLI 记录规则、SLO 元数据规则和多窗口多燃烧率告警规则。
参考:1、 https://www.51cto.com/article/674806.html 2、https://github.com/google/prometheus-slo-burn-example 3、https://github.com/slok/sloth?tab=readme-ov-file
来源:程序园用户自行投稿发布,如果侵权,请联系站长删除 免责声明:如果侵犯了您的权益,请联系站长,我们会及时删除侵权内容,谢谢合作! |


[CISCN 2022 华东北]duck 一、题目来源 NSSCTF-Pwn-[CISCN 2022 华东北]duck 二、信息搜集 通过 file 命令查看文件类型: 通过 checksec 命令查看文件开启的保护机制: 题目把 libc 文件和链接器都给我们了,我原
前言 在信息碎片化的今天,微信公众号依然是高质量中文内容的重要来源。然而,微信生态的封闭性使得我们难以通过习惯的 RSS 阅读器聚合阅读。WeRSS 是一个优秀的开源项目,致力于打破这一壁垒,它通过模拟请求